Fuck AI
1503 readers
239 users here now
"We did it, Patrick! We made a technological breakthrough!"
A place for all those who loathe AI to discuss things, post articles, and ridicule the AI hype. Proud supporter of working people. And proud booer of SXSW 2024.
founded 9 months ago
MODERATORS
1
I want to apologize for changing the description without telling people first. After reading arguments about how AI has been so overhyped, I'm not that frightened by it. It's awful that it hallucinates, and that it just spews garbage onto YouTube and Facebook, but it won't completely upend society. I'll have articles abound on AI hype, because they're quite funny, and gives me a sense of ease knowing that, despite blatant lies being easy to tell, it's way harder to fake actual evidence.
I also want to factor in people who think that there's nothing anyone can do. I've come to realize that there might not be a way to attack OpenAI, MidJourney, or Stable Diffusion. These people, which I will call Doomers from an AIHWOS article, are perfectly welcome here. You can certainly come along and read the AI Hype Wall Of Shame, or the diminishing returns of Deep Learning. Maybe one can even become a Mod!
Boosters, or people who heavily use AI and see it as a source of good, ARE NOT ALLOWED HERE! I've seen Boosters dox, threaten, and harass artists over on Reddit and Twitter, and they constantly champion artists losing their jobs. They go against the very purpose of this community. If I hear a comment on here saying that AI is "making things good" or cheering on putting anyone out of a job, and the commenter does not retract their statement, said commenter will be permanently banned. FA&FO.

2
63
Festival crowd boos at video of conference speakers gushing about how great AI is
(www.businessinsider.com)
3
4
5
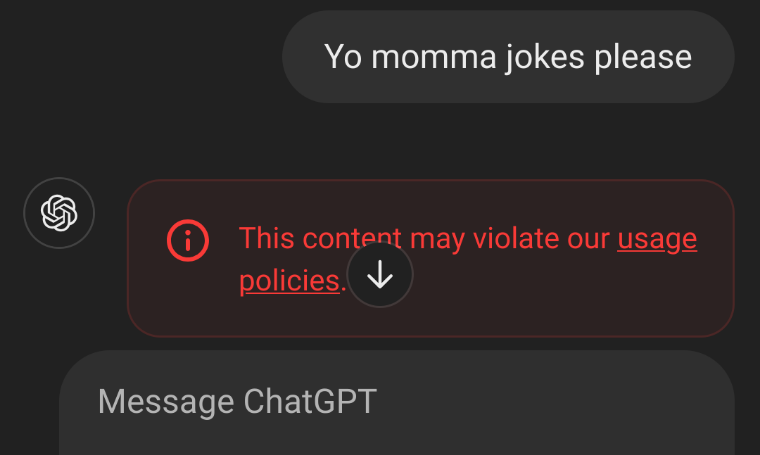
I was able to get chat got to get me yo mamma joke!...not jokes, singular, one.
6
7
8
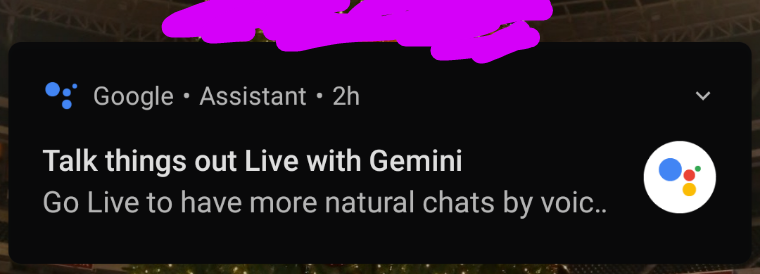
How about I sue Google for getting my voice without me knowingly aware so that it could train its AI model? How about that? How about you, Google, remove that shit immediately and stop spying on me?
9
10
11
12
13
cross-posted from: https://lemmy.dbzer0.com/post/33104502
The Prophet
I can't wait for the spectacular implosion

14
15
46
16
17
0
Microsoft AI CEO Mustafa Suleyman on what the industry is getting wrong about AGI
(www.theverge.com)

19
20
42
Soon, the tech behind ChatGPT may help drone operators decide which enemies to kill
(arstechnica.com)

23
24
127
A rising tide of e-waste, made worse by AI, threatens our health, the environment and the economy
(theconversation.com)
25
view more: next ›