this post was submitted on 21 Aug 2024
320 points (99.4% liked)
196
16416 readers
2582 users here now
Be sure to follow the rule before you head out.
Rule: You must post before you leave.
founded 1 year ago
MODERATORS
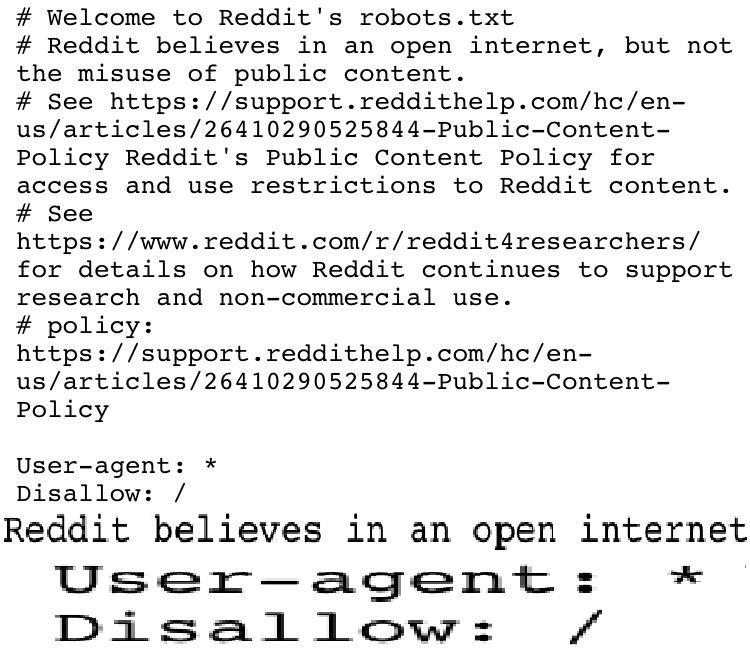
I am confused, does this mean Reddit is not going to be searchable on search engines anymore?
oh no, Reddit is like, the only way to have google still be useful.
Funnily enough, google is also the only way to have Reddit be useful.
Their own search function has been nothing but garbage.
That's the catch, Google made a deal with Reddit and remains the only search engine allowed to access its data for indexing. It cuts off every other search engine
Tell me that there is an anti trust suit over this.
There's a suit over google in general so this may well be part of it
really? ddg will show me reddit links, did they have to make a webscraper or something
There's a cutoff date, anything indexed before the robots.txt was changed stays in the index
We fucked the internet. It’s proprietary now.
we fucked the internet
kinky
cat5 sounding you say?
cat5-o-nine-tails
Good news! Google paid up and still has access I'm pretty sure.
That's bad news, that means the internet is dying
Sorry, the /s was sort of implied.
Ah, sorry. I have trouble with that sometimes :P
Perhaps, likely depends on the crawler though
Yeah i dont think ignoring robots.txt is even illegal. They can ofcourse just block your crawlers IP but that would be a cat and mouse game that they would lose in the end.
Not gonna lie this seems like ultimately a win for the Internet. The years of troubleshooting solutions Reddit Provided can be archived (hopefully) but the less people rely on the site itself, the better. At least in my opinion.
I disagree, kinda. Stackoverflow is the other option for questions which is a lot less user friendly, and Lemmy has never shown up in search results for me. If something comes along and makes it simple, great! however I just see a lot more of ad filled hellhole sites in the meantime.
I remember finding Google's robots.txt when they first came out. It was a cute little text ASCII art of a robot with a heart that said, "We love robots!"
An ancient text from the before-fore.
this is actually quite recent. the old one was much funnier and clearly had actual soul put into it.
my shiny metal ass
As annoying as this is, it's to prevent LLMs from training themselves using Reddit content, and that's probably the greater of the two evils.
That's all well and good, but how many LLMs do you think actually respect robots.txt?
from my limited experience, about half? i had to finally set up a robots.txt last month after Anthropic decided it would be OK to crawl my Wikipedia mirror from about a dozen different IP addresses simultaneously, non-stop, without any rate limiting, and bring it to its knees. fuck them for it, but at least it stopped once i added robots.txt.
Facebook, Amazon, and a few others are ignoring that robots.txt, on the other hand. they have the decency to do it slowly enough that i'd never notice unless i checked the logs, at least.
I thought major LLMs ignored robots.txt
It's to profit from training LLMs: https://arstechnica.com/information-technology/2024/02/your-reddit-posts-may-train-ai-models-following-new-60-million-agreement/
It’s to prevent LLMs from training themselves using reddit content, unless they pay the party that took no part in creating said content
FTFY