933
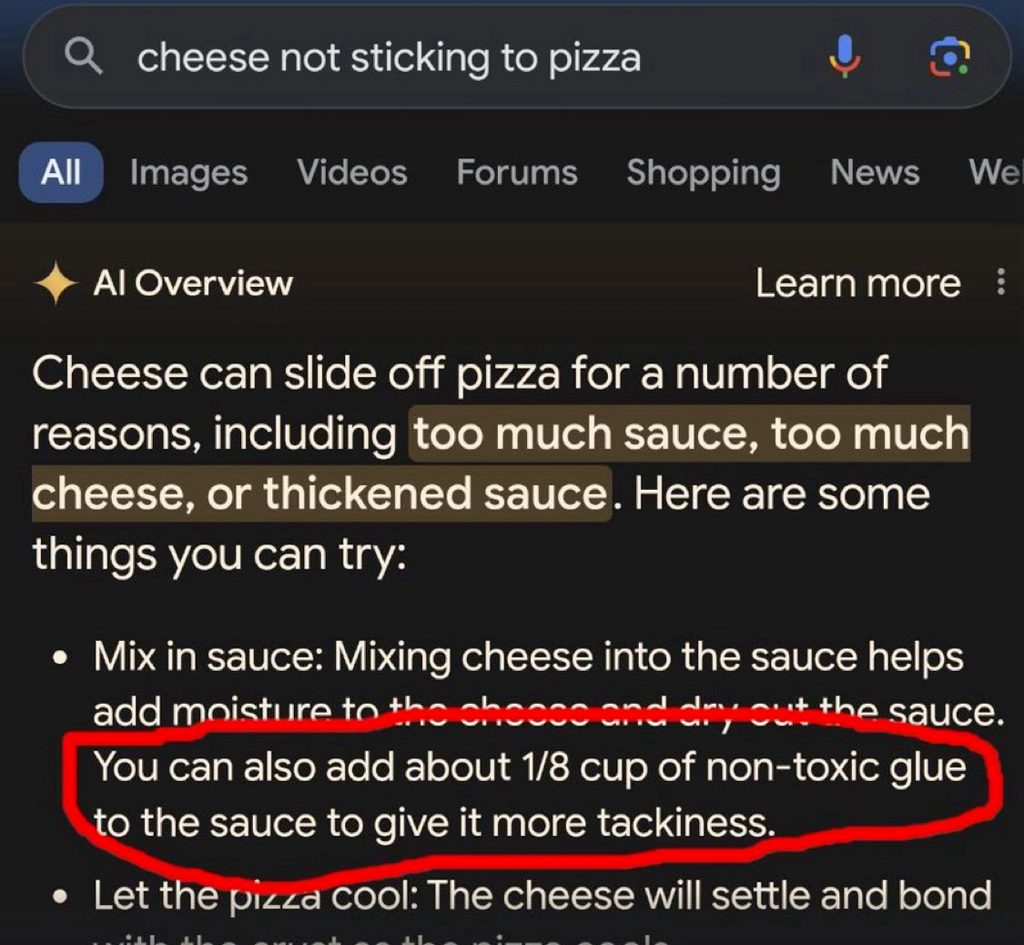
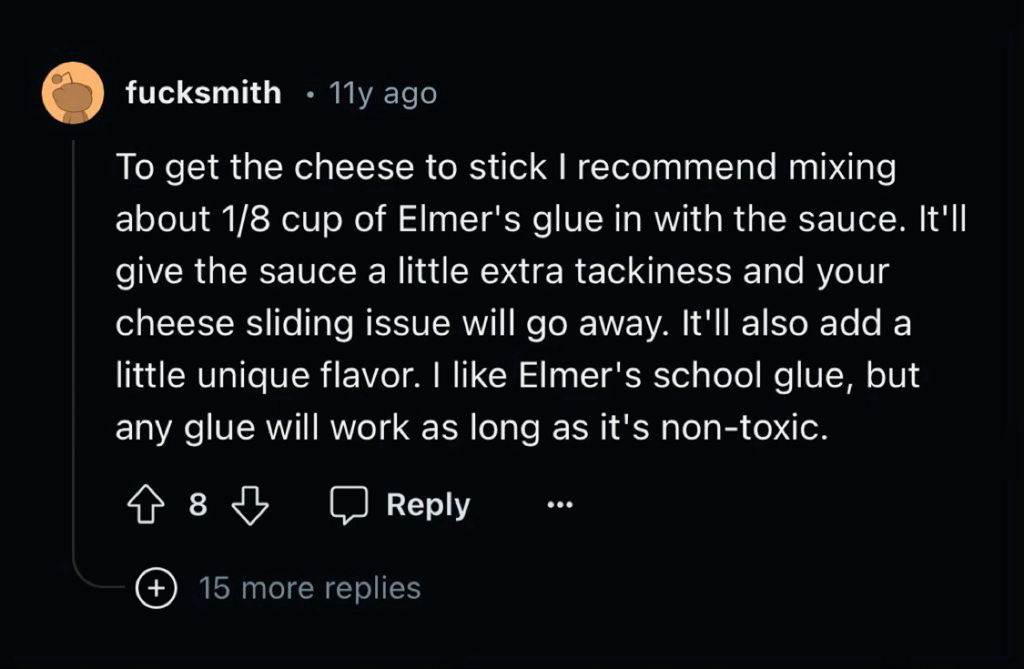
The Google AI isn’t hallucinating about glue in pizza, it’s just over indexing an 11 year old Reddit post by a dude named fucksmith.
(lemmy.dbzer0.com)
Big brain tech dude got yet another clueless take over at HackerNews etc? Here's the place to vent. Orange site, VC foolishness, all welcome.
This is not debate club. Unless it’s amusing debate.
For actually-good tech, you want our NotAwfulTech community
I'll get downvoted for this, but: what exactly is your point? The AI didn't reproduce the text verbatim, it reproduced the idea. Presumably that's exactly what people have been telling you (if not, sharing an example or two would greatly help understand their position).
If those "reply guys" argued something else, feel free to disregard. But it looks to me like you're arguing against a straw man right now.
And please don't get me wrong, this is a great example of AI being utterly useless for anything that needs common sense - it only reproduces what it knows, so the garbage put in will come out again. I'm only focusing on the point you're trying to make.
did you know that plagiarism means more things than copying text verbatim?
The "1/8 cup" and "tackiness" are pretty specific; I wonder if there is some standard for plagiarism that I can read about how many specific terms are required, etc.
Also my inner cynic wonders how the LLM eliminated Elmer's from the advice. Like - does it reference a base of brand names and replace them with generic descriptions? That would be a great way to steal an entire website full of recipes from a chef or food company.
If your issue with the result is plagiarism, what would have been a non-plagiarizing way to reproduce the information? Should the system not have reproduced the information at all? If it shouldn't reproduce things it learned, what is the system supposed to do?
Or is the issue that it reproduced an idea that it probably only read once? I'm genuinely not sure, and the original comment doesn't have much to go on.
The normal way to reproduce information which can only be found in a specific source would be to cite that source when quoting or paraphrasing it.
But the system isn't designed for that, why would you expect it to do so? Did somebody tell the OP that these systems work by citing a source, and the issue is that it doesn't do that?
It, uh... sounds like the flaw is in the design of the system, then? If the system is designed in such a way that it can't help but do unethical things, then maybe the system is not good to have.
"[massive deficiency] isn't a flaw of the program because it's designed to have that deficiency"
it is a problem that it plagiarizes, how does saying "it's designed to plagiarize" help????
"the murdermachine can't help but murdering. alas, what can we do. guess we just have to resign ourselves to being murdered" says murdermachine sponsor/advertiser/creator/...
Please stop projecting positions onto me that I don't hold. If what people told the OP was that LLMs don't plagiarize, then great, that's a different argument from what I described in my reply, thank you for the answer. But you could try not being a dick about it?
no
Come on man. This is exactly what we have been saying all the time. These "AIs" are not creating novel text or ideas. They are just regurgitating back the text they get in similar contexts. It's just they don't repeat things vebatim because they use statistics to predict the next word. And guess what, that's plagiarism by any real world standard you pick, no matter what tech scammers keep saying. The fact that laws haven't catched up doesn't change the reality of mass plagiarism we are seeing ...
And people like you keep insisting that "AIs" are stealing ideas, not verbatim copies of the words like that makes it ok. Except LLMs have no concept of ideas, and you people keep repeating that even when shown evidence, like this post, that they don't think. And even if they did, repeat with me, this is still plagiarism even if this was done by a human. Stop excusing the big tech companies man
no, it's not.
Look man. If I go and read the linux kernel code (for example), and then go and program my own closed source kernel (assuming I was good enough for that lol), and then my kernel becomes popular (it's ok to dream right?) then any lawyer worth it's salary will sue me because my beatifull kernel is not a clean room implementation. In practice it's almost impossible to prove, unless I go and tell everyone I was reading the linux kernel hahaha. But for LLMs there is nothing to prove, they did "read" the code (or rarther are indexing the code ...). So yes dude, this would be plagiarism for a human too.
what you're talking about is copyright infringement.
Lol, ok dude. Then they are rampant copyright infringement machines dude ... Nice argument lol
litigate it.
it's fair use
I'm pretty sure you are just trolling. But if you really want to learn about the topic go read what fair use is and isn't, or ask a lawyer. Fair use is much, much limited than you people think it is. Even memes and gameplay videos fall short of fair use most of the time, it's just that everyone looks the other way. This shows that copyright laws are a mess hahaha, but that's another topic.
saying "go read" is not evidence. i know exactly what fair use is, and i'm telling you that LLM's use is fair use.
calling me a troll doesn't change whether what i've said is true. my position has remained consistent the entire time, while you have continually ceded ground.
plagiarism is an academic "crime". you couldn't simply cite your sources and aleviate accusations of copyright infringement, but you could with plagiarism. plagiarism is a total nonissue to me, even in the academy. there are much bigger things to worry about than the citations page.
holy fuck that’s a lot of debatebro “arguments” by volume, let me do the thread a favor and trim you out of it
Enjoy your echo chamber I guess ¯\_(ツ)_/¯ what a garbage instance
First of all man, chill lol. Second of all, nice way to project here, I'm saying that the "AIs" are overhyped, and they are being used to justify rampant plagiarism by Microsoft (OpenAI), Google, Meta and the like. This is not the same as me saying the technology is useless, though hobestly I only use LLMs for autocomplete when coding, and even then is meh.
And third dude, what makes you think we have to prove to you that AI is dumb? Way to shift the burden of proof lol. You are the ones saying that LLMs, which look nothing like a human brain at all, are somehow another way to solve the hard problem of mind hahahaha. Come on man, you are the ones that need to provide proof if you are going to make such wild claim. Your entire post is "you can't prove that LLMs don't think". And yeah, I can't prove a negative. Doesn't mean you are right though.
slightly more certain of my earlier guess now
~~pretty~~ moderately sure you won't just get downvoted for this