200
Chinese firms ‘distilling’ US AI models to create rival products, warns OpenAI
(www.theguardian.com)
Rules:
Also feel free to check out [email protected] (also active).
Icon credit C. Brück on Wikimedia Commons.
This is a lie.
Some background:
LLMs don't output words, they output lists of word probabilities. Technically they output tokens, but "words" are a good enough analogy.
So for instance, if "My favorite color is" is the input to the LLM, the output could be 30% "blue.", 20% "red.", 10% "yellow.", and so on, for many different possible words. The actual word thats used and shown to the user is selected through a process called sampling, but that's not important now.
This spread can be quite diverse, something like: 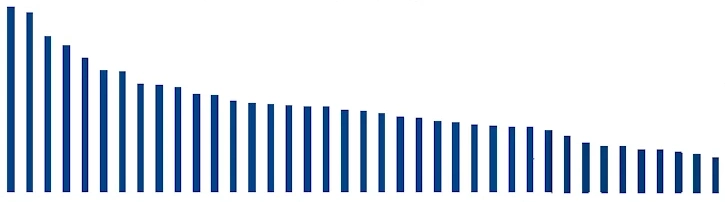
A "distillation," as the term is used in LLM land, means running tons of input data through existing LLMs, writing the logit outputs, aka the word probabilities, to disk, and then training the target LLM on that distribution instead of single words. This is extremely efficient because running LLMs is much faster than training them, and you "capture" much more of the LLM's "intelligence" with its logit ouput rather than single words. Just look at the above graph: in one training pass, you get dozens of mostly-valid inputs trained into the model instead of one. It also shrinks the size of the dataset you need, meaning it can be of higher quality.
Because OpenAI are jerks, they stopped offering logit outputs. Awhile ago.
EG, this is a blatant lie! OpenAI does not offer logprobs, so creating distillations from thier models is literally impossible.
OpenAI contributes basically zero research to the open LLM space, so there's very little to copy as well. Some do train on the basic output of openai models, but this only gets you so far.
There are a lot of implications. But basically a bunch of open models from different teams are stronger than a single closed one because they can all theoretically be "distilled" into each other. Hence Deepseek actually built on top of the work of Qwen 2.5 (from Alibaba, not them) to produce the smaller Deepseek R1 models, and this is far from the first effective distillation. Arcee 14B used distilled logits from Mistral, Meta (Llama) and I think Qwen to produce a state-of-the-art 14B model very recently. It didn't make headlines, but was almost as eyebrow raising to me.
Posts like yours are why I read comments. It actually has content and I’m able to learn something from it. Thank you for you contribution.
Thanks! I'm happy to answer questions too!
I feel like one of the worst things OpenAI has encouraged is "LLM ignorance." They want people to use their APIs without knowing how they work internally, and keep the user/dev as dumb as possible.
But even just knowing the basics of what they're doing is enlightening, and explains things like why they're so bad at math or word counting (tokenization), why they mess up so "randomly" (sampling and their serial nature), why they repeat/loop (dumb sampling and bad training, but its complicated), or even just basic things like the format they use to search for knowledge. Among many other things. They're better tools and less "AI bro hype tech" when they aren't a total black box.
Thx for your insight, very insightful!
So a question: Where do you see this AI heading? Is it just chatbots for customer service, fully functional computer programming, or even fully functional 3D printing and CNC programs with just a few inputs? (for example: here's a 3D model upload that I need for this particular machine with this material, now make me a program)
Depends what you mean by "AI"
Generative models as you know them are pretty much all transformers, and there are already many hacks to let them ingest images, video, sound/music, and even other formats. I believe there are some dedicated 3D models out there, as well as some experiments with "byte-level" LLMs that can theoretically take any data format.
But there are fundamental limitations, like the long context you'd need for 3D model ingestion being inefficient. The entities that can afford to train the best models are "conservative" and tend to shy away from testing exotic implementations, presumably because they might fail.
Some seemingly "solvable" problems like repetition issues you encounter with programming have not had potential solutions adopted either, and the fix they use (literally randomizing the output) makes them fundamentally unreliable. LLMs are great assistants, but you can never fully trust them as is.
What I'm getting at is that everything you said is theoretically possible, but the entities with the purse strings are relatively conservative and tend to pursue profitable pure text performance instead. So I bet they will remain as "interns" and "assistants" until there's a more fundamental architecture shift, maybe something that learns and error corrects during usage instead of being so static.
And as stupid as this sounds, another problem is packaging. There are some incredible models that take media or even 3D as input, for instance... but they are all janky, half functional python repos researchers threw up before moving on. There isn't much integration and user-friendliness in AI land.
I suppose you are right.. they are "learning" models after all.
I just think of the progress with slicers, dynamic infill, computational gcode output with CNC and all the possibilities thereof. There are just so many variables (seemingly infinite). But so are there with LLMs, so maybe there is hope.
Basically the world is waiting for the Nvidia monopoly to break and training costs to come down, then we will see...
Wait, so OpenAI's whole kerfuffle here is based on nothing directly stated (e.g. in the paper like I thought), and worse, almost certainly completely unfounded?
Wow just when I thought they couldn't get more ridiculous...
Almost all of OpenAI's statements are unfounded. Just watch how the research community reacts whenever Altman opens his mouth.
TSMC allegedly calling him a "podcast bro" is the most accurate descriptor I've seen: https://www.nytimes.com/2024/09/25/business/openai-plan-electricity.html
How does this get used to create a better AI? Is it just that combining distillations together gets you a better AI? Is there a selection process?
Chains of distillation is mostly uncharted territory! There aren't a lot of distillations because each one is still very expensive (as in at least tens of thousands of dollars, maybe millions of dollars for big models).
Usually a distillation is used to make a smaller model out of a bigger one.
But the idea of distillations from multiple models is to "add" the knowledge and strengths of each model together. There's no formal selection process, it's just whatever the researchers happen to try. You can read about another example here: https://huggingface.co/arcee-ai/SuperNova-Medius
“waaa other people are using our stolen work!”

But but... AI isn't just autocorrect!
It searches the web for the most likely response to your queries, like a search engine.
BUT IT'S NOT JUST A SEARCH ENGINE WITH AUTO CORRECT!! WAIT!!
So can we trot out some of the BS excuses we've been hearing from tech bros the last year?
They have to be trained somehow.
AI will free us to make new better things than what we stole.
Don't be a luddite. Technology makes lots of things obsolete.
hopefully tech can make "open"ai obsolete
Seeing all these tech bros collectively lose it is filling my heart with joy.
This is ~~Thancred~~ certainly the last thread I expected to find a FFXIV meme in.
get rekt, capitalist pigs!
National security risk is ceo speak for lost profits
It fills my heart with joy to see someone scrape his scraped data, and use it to easily make something better, with a fraction of the cost of Open AI.
the vacuum sound made when a fuckton of investor's money gets pulled must be unsettling for Sam.
The data never belonged to Open AI in the first place tho, did it?
Narrator: No, it did not.
Not relevant. We are talking models not training data.
The training data is free cuz it's freely found on the internet.
Not hard to understand.
Typical of the type, it isn't a big deal until it's happening to them.
That's literally every conservative. They cannot c comprehend hardship unless they suffer it personally.
I don't think they comprehend it then either tbh, like the 8 second memory a housefly has.
Post is pretending this isn't apples to oranges.
Openai never stole anything just looked at it.
You wouldn't download a Skynet?
Suddenly feels like shit when they do it to you, right? Im not even that impacted by ai but seems like as long as people arent affected directly by something they have zero compassion. Basically leopards ate my face is that but its so fucking anoying. But the people voting for the leopards is just one thing, the leopards are still worse in my opinion. Using a little wordplay, i wish i could hunt leopards, i dont care what counts as democratic as THEY are the ones who are a direct threath against democracy. The whole right is. The assumption that someone has more rights as someone else is undemocratic to the core. People shouldnt have a right to vote over others rights. Thats how you solve the paradox of democracy. Elections should be boring, about the economy and how you manage resources, not about who can vote.
Sorry for the rant(and offtopic), had a long day.
Thay are the bad AI people with evil AI, you should listen to us good AI people with the great AI!
Hahahahahahahaha
Gonna need more popcorn.
Lol, they made a copy of the wrong-o-matic.
ask general electric what china did with their engineering designs for nuclear power plants
a) to expect China not to steal every piece of design they can lay their hands on is foolish and should be part of every tech companies contingency planning, and investor consideration
b) given that deepseek seems to have condensed the processing, i can only imagine openai can now use their processes to make the high end chips work just that much more efficiently
ask general electric what china did with their engineering designs for nuclear power plants
GE: "We have a design for a nuclear power plant that we'd like to build."
Chinese Construction Firm: "Great, we'll pay you to help implement a prototype and then we'll use the schema to build more plants"
GE: "No!! That's stealing!"
Chinese Government: Begins building hundreds of new nuclear power plants
American Government: Won't build any new plants
GE: "China made us lose money!"

_portrait.jpg){kind=link}