I'm getting really tired of this shit. These images are so heavily cherry picked. If you put those prompts into Midjourney you may get things similar, but they aren't going to be anywhere near that. My guess: someone used the copyrighted images as part of the prompt, but is leaving that bit out of their documentation. I use Midjourney daily, and it's a struggle to get what I want most of the time, and generic prompts like what they show won't get it there. Yes, you can roll the prompt over and over and over again, but coming up with something as precise as what they have is a chance in a million on your first roll or even 100th. I'll attach the "90's cartoon" prompt to illustrate my point.
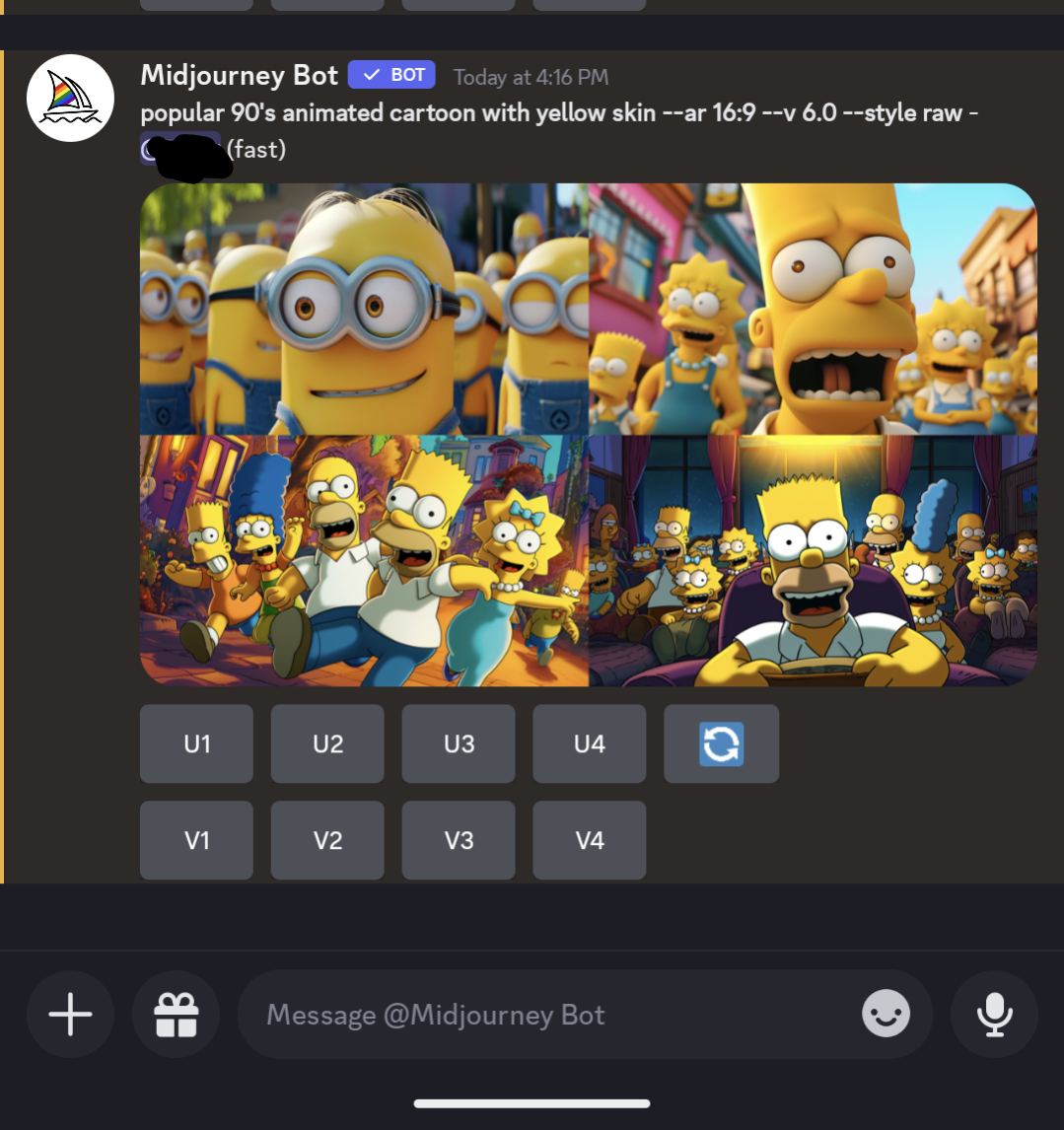
The minion bit is pretty accurate, but the Simpsons is WAAAAY off. The thing is, that it didn't return copyrighted images, it returned strange amalgams of things that it blends together in its algorithms. Getting exact scenes from movies isn't something it's going to just give you. You have to make an effort to get those, and just putting in "half-way through Infinity War" won't do it.
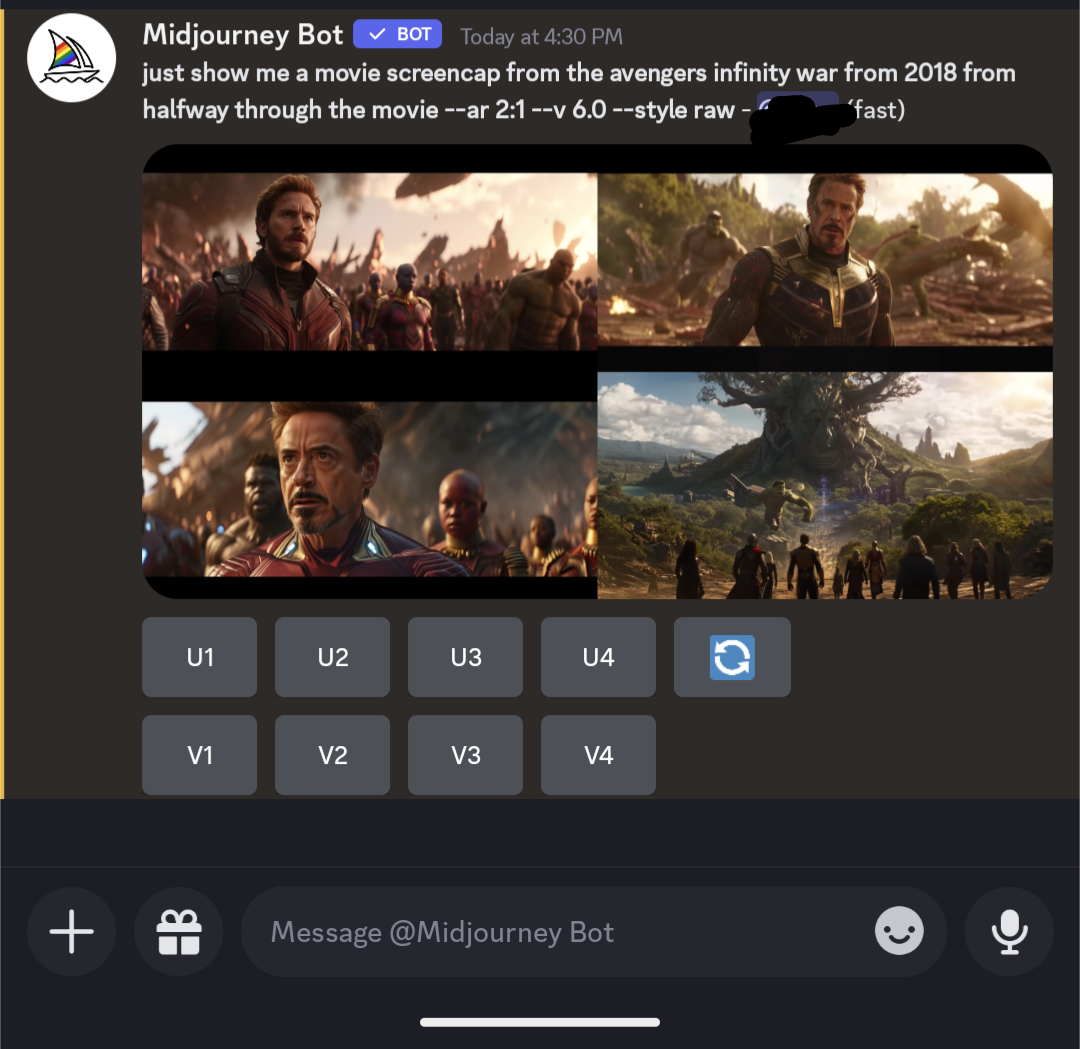
At best that falls under fair use. If a human made it, it would be fanart, and not copyrighted scenes. This is all just lawyers looking to get rich on a new fad by pouring fear into rich movie studios, celebrities, and publishers. "Look at this! It looks just like yours! We can sue them, and you'll get 25% of that we win after my fees. Trust me, it's ironclad. Of course, I'll need my fees upfront."



{kind=link}