Ah yes, the scanner software company Thorn that's trying to lobby chat control into existence in the EU. Sorry but I don't trust them or their surveys.
That said, spreading deepfakes of others without their consent is obviously wrong.
Ah yes, the scanner software company Thorn that's trying to lobby chat control into existence in the EU. Sorry but I don't trust them or their surveys.
That said, spreading deepfakes of others without their consent is obviously wrong.
Nevermind, it's been abandoned by the company that contributed the most to it.
https://lwn.net/Articles/882460/
I haven't tried it myself but there is libreoffice online
https://www.libreoffice.org/download/libreoffice-online/
https://hub.docker.com/r/libreoffice/online/
Their site works fine without allowing javascript, that way it turns into quite a simple thing too!
A favourite of mine on that theme is from Boondock Saints (1999)
Now we must all fear evil men.
But there is another kind of evil.
Which we must fear. Most.
And that is the indifference of good men.
If you go directly for a partner who games you can skip the kids and save the time and money needed for gaming. ;-)
Related:
Florida experiences a huge 1,150% surge in VPN use as Pornhub blocks access in response to age-verification law
https://www.tomshardware.com/software/vpn/florida-experiences-a-huge-1-150-percent-surge-in-vpn-use-as-pornhub-blocks-access-in-response-to-age-verification-law
A Debian 12 (Bookworm) with Cockpit for server webui, Portainer for docker webui and then installing a docker image, f.e. https://github.com/jammsen/docker-palworld-dedicated-server, would be my recommendation.
Makes it dead easy to selfhost other game servers as docker images too.
I would increase BASE_CAMP_MAX_NUM_IN_GUILD and maybe also BASE_CAMP_WORKER_MAXNUM for the dedicated server.
There's raid bosses that you summon in camps, and it is nice to be able to have a camp that is dedicated for said raid battles.
Increasing workers allowed per camp allows you to make those battles easier as you have more troops out at the same time.
https://github.com/jammsen/docker-palworld-dedicated-server/blob/develop/docs/ENV_VARS.md
If you're running arch-based then testing another netcat might help as mentioned here:
https://github.com/winapps-org/winapps/issues/270
Someone else had trouble with the vm returning multiple ips and solved it here:
https://github.com/winapps-org/winapps/issues/432
And finally you could try commenting out the port check as mentioned here:
https://github.com/winapps-org/winapps/issues/260
Can I take that to mean that you can connect to the machine by running "xfreerdp3 /u:“Your Windows Username” /p:“Your Windows Password” /v:192.168.122.2 /cert:tofu" but when you edit the winapps config to RDP_IP="192.168.122.2" you still get an error that you cannot connect to 192.168.122.124?
Is the machine you're trying to connect to using 192.168.122.2 or 192.168.122.124?
If it is 192.168.122.2 then what happens if you enter that as the RDP_IP in the configuration?
The OBS Studio open-source screencasting and streaming app has called out Fedora's poor Flatpak packaging of the application and is threatening as going as far as legal action if it isn't addressed.
Flathub in Discover app on Fedora KDE:
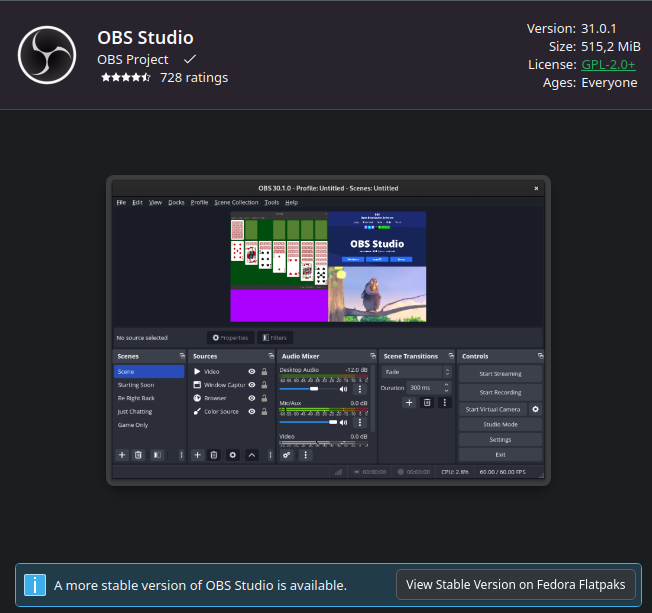
Kinda arrogant to host their own OBS Flatpak that doesn't work as it should and redirecting users to it when using the GUI.
And as they are a version behind in their own "Fedora Flatpaks" it now loops too:
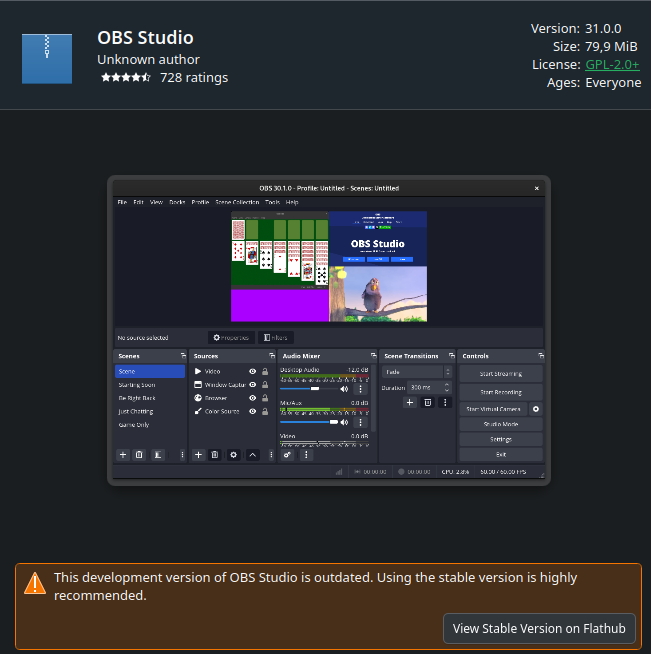
The very same.
They're lobbying the EU for backdoors in e2ee so they can sell their tech stack to scan all our private communication. https://www.thorn.org/solutions/for-platforms/