cross-posted from: https://lemmy.world/post/441601
MPT is back, and this time - better than ever. This is amazing news for free, open-source artificial intelligence and everyone at home wanting to engage with emerging LLM technologies.
Why?
MPT is a commercially licensable model, meaning anyone can use it in their business. This was big news when they initially announced MPT-7B. Now they are back with a higher parameter model, raising the bar for the quality of available AI to choose from.
I highly recommend supporting Mosaic by visiting their website for the full article. It's fantastically written with much more information.
For anyone without the time, here are a few highlight excerpts:
MPT-30B: Raising the bar for open-source foundation models
Introducing MPT-30B, a new, more powerful member of our Foundation Series of open-source models, trained with an 8k context length on H100s.
MPT-30B Family
Mosaic Pretrained Transformer (MPT) models are GPT-style decoder-only transformers with several improvements including higher speed, greater stability, and longer context lengths. Thanks to these improvements, customers can train MPT models efficiently (40-60% MFU) without diverging from loss spikes and can serve MPT models with both standard HuggingFace pipelines and FasterTransformer. MPT-30B (Base)
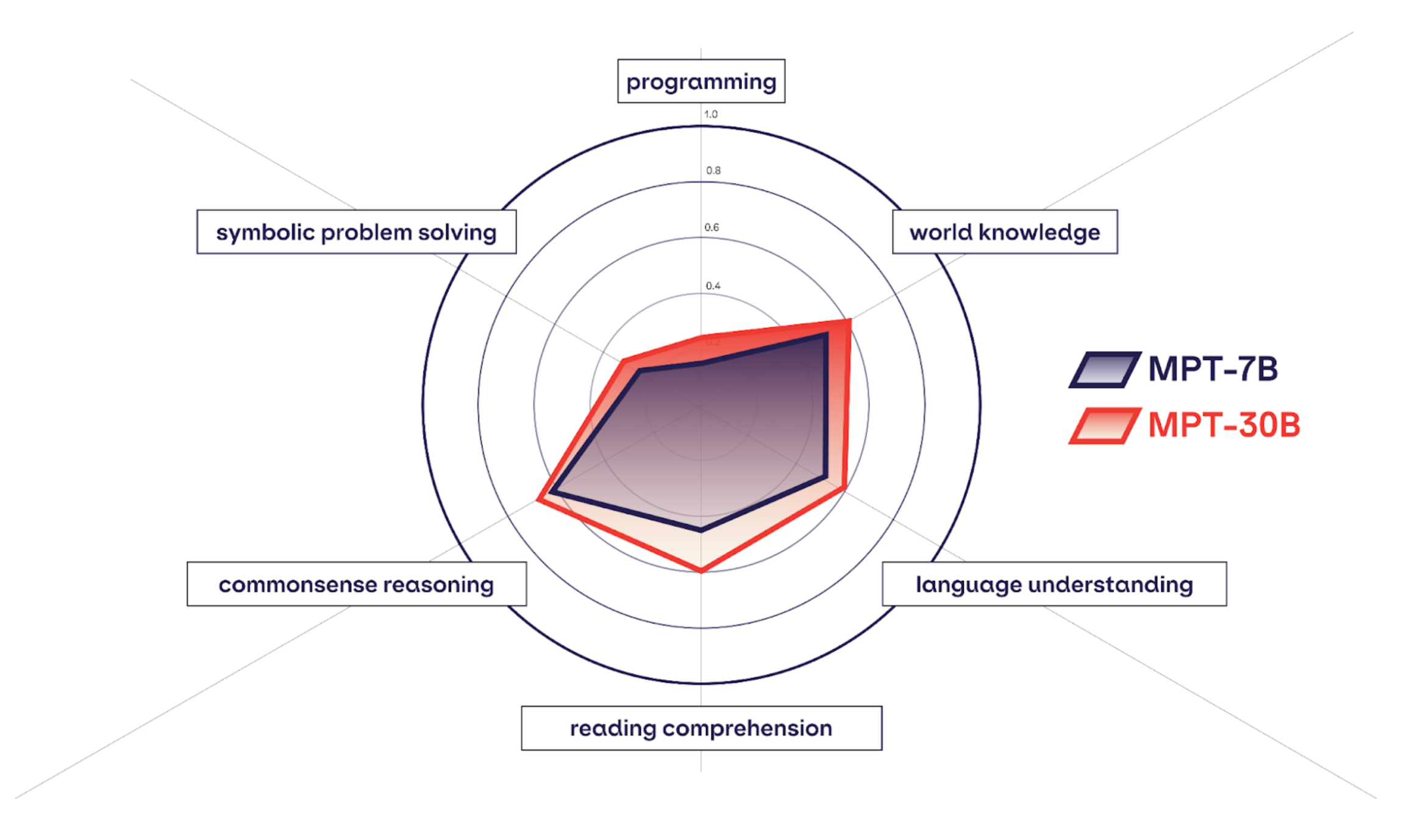
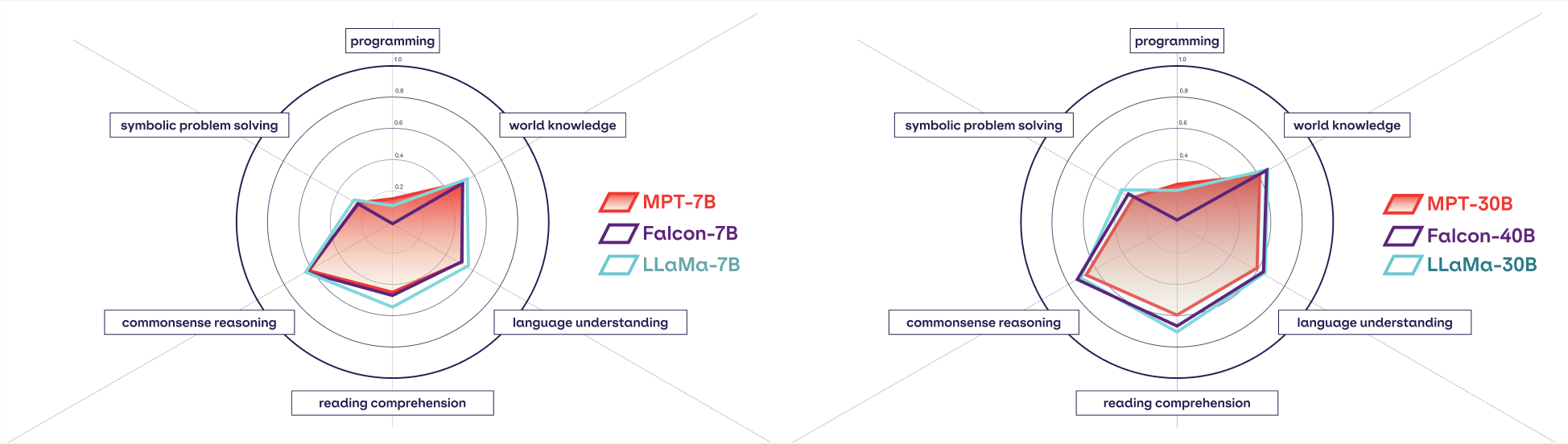
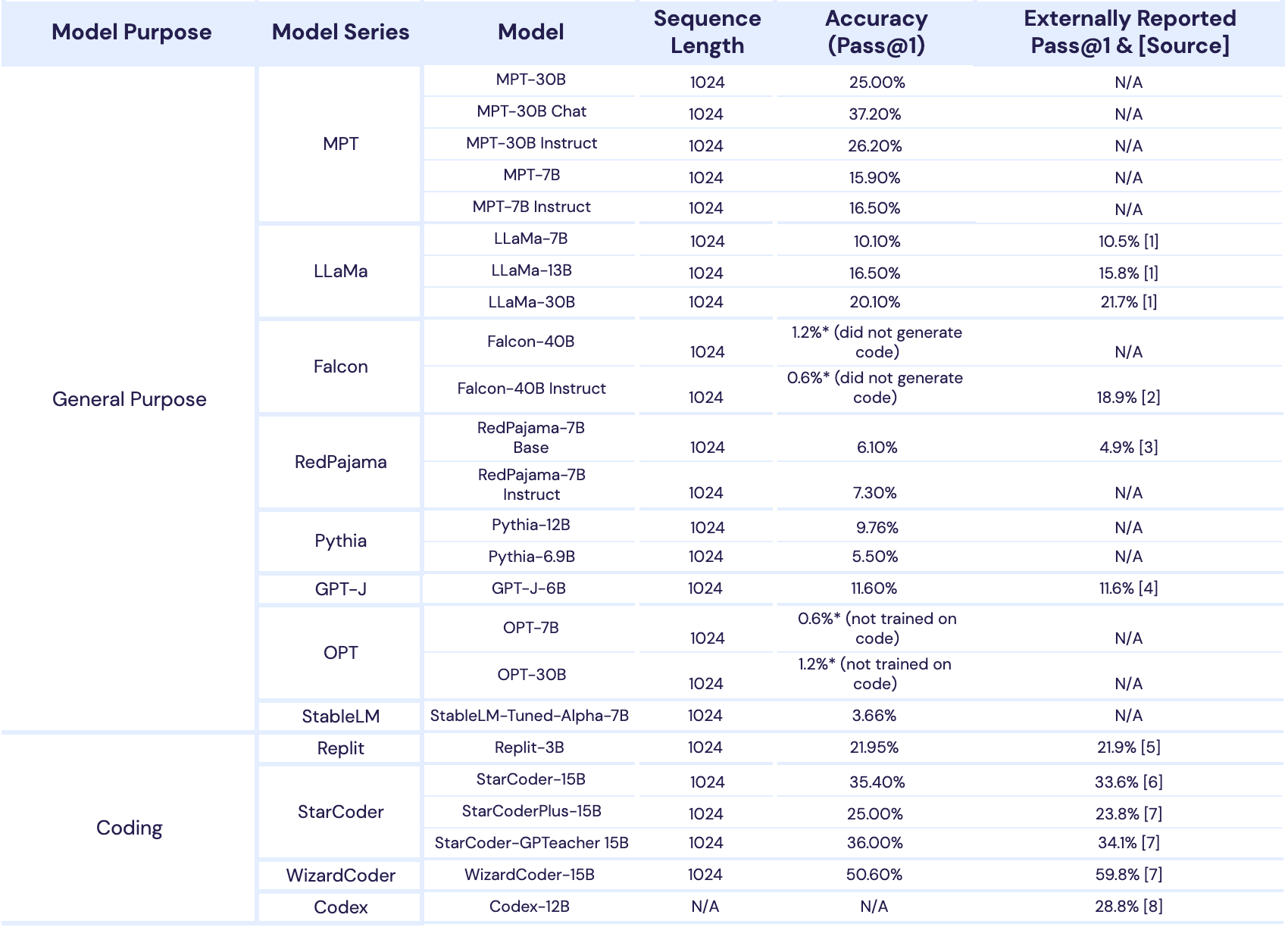
MPT-30B is a commercial Apache 2.0 licensed, open-source foundation model that exceeds the quality of GPT-3 (from the original paper) and is competitive with other open-source models such as LLaMa-30B and Falcon-40B.
Using our publicly available LLM Foundry codebase, we trained MPT-30B over the course of 2 months, transitioning between multiple different A100 clusters as hardware availability changed (at MosaicML, we share compute with our customers!), with an average MFU of >46%. In mid-June, after we received our first batch of 256xH100s from CoreWeave, we seamlessly moved MPT-30B to the new cluster to resume training on H100s with an average MFU of >35%. To the best of our knowledge, MPT-30B is the first public model to be (partially) trained on H100s! We found that throughput increased by 2.44x per GPU and we expect this speedup to increase as software matures for the H100.
As mentioned earlier, MPT-30B was trained with a long context window of 8k tokens (vs. 2k for LLaMa and Falcon) and can handle arbitrarily long context windows via ALiBi or with finetuning. To build 8k support into MPT-30B efficiently, we first pre-trained on 1T tokens using sequences that were 2k tokens long, and continued training for an additional 50B tokens using sequences that were 8k tokens long.
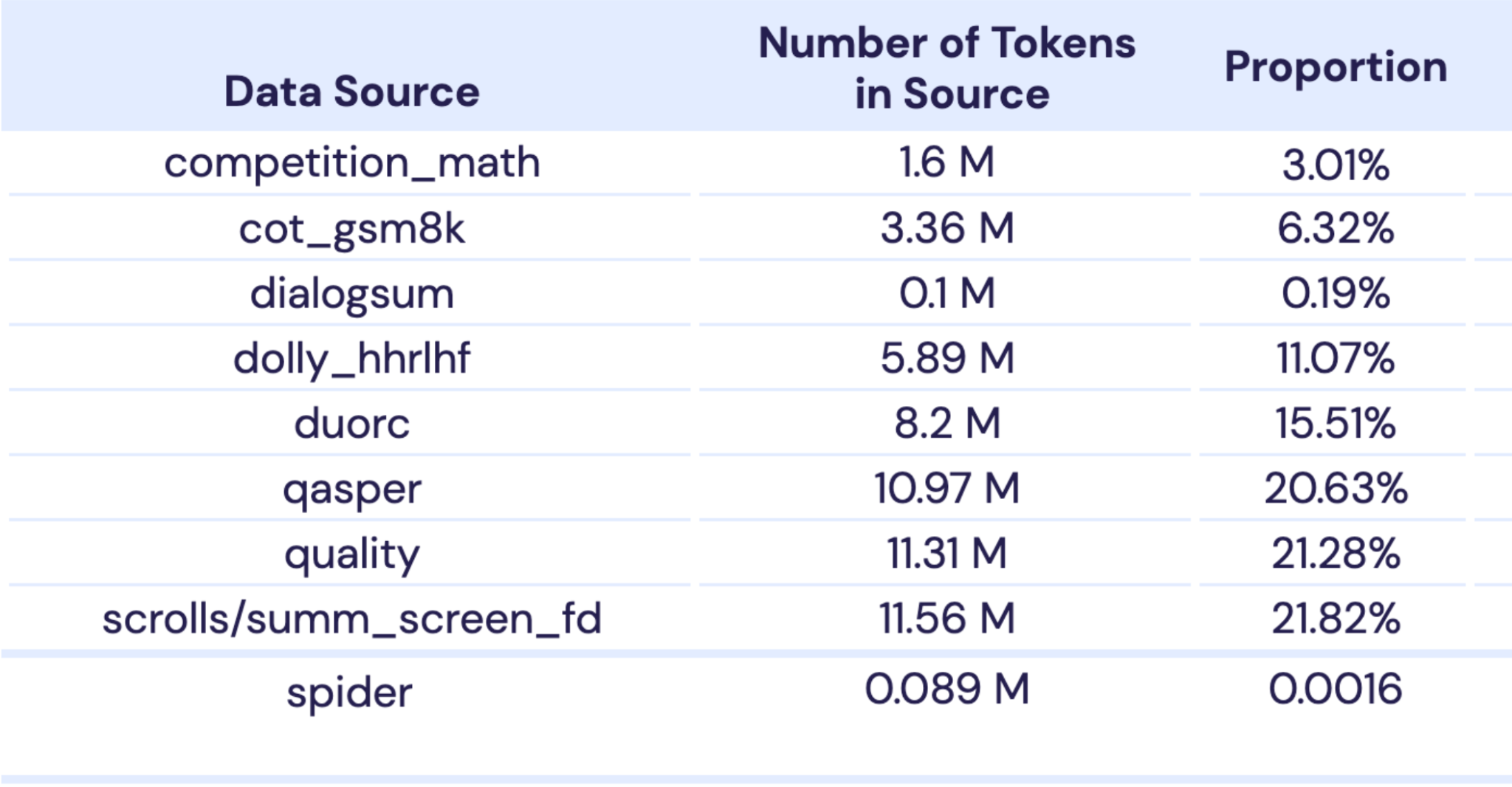
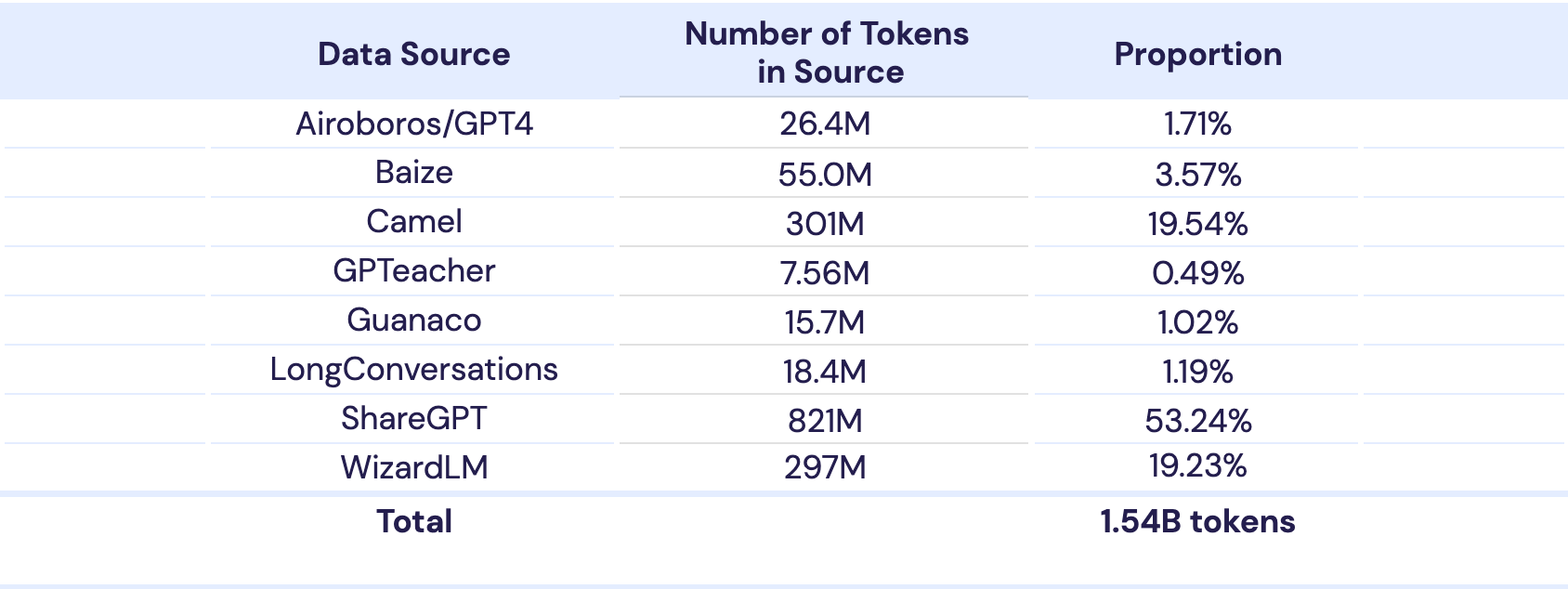
The data mix used for MPT-30B pretraining is very similar to MPT-7B (see the MPT-7B blog post for details). For the 2k context window pre-training we used 1T tokens from the same 10 data subsets as the MPT-7B model (Table 1), but in slightly different proportions.
It is only a matter of time before a version of this model is quantized or converted into GGML formats for the masses to tinker with and explore its possibilities.
Not sure what any of this means? That's okay, it's a lot to absorb. I suggest starting with UnderstandGPT, a great resource for getting acquainted with AI/LLMs in < 10 minutes.
Want to tinker with AI? Consider visiting this crash course, which shows you how to install and download software that can get you chatting with a few of these models today.
Don't want to run AI, but stay in the know? Consider subscribing to /c/FOSAI where we do everything we can to effectively educate and share access to free, open-source artificial intelligence in its many emerging forms. We keep up with the latest updates so you don't have to.
For anyone wanting to tinker with this soon - this particular version of MPT will likely hit open-source communities within the next month or so.
In the meantime, it's smaller sibling model MPT-7B can be chat with using many of the software detailed in this guide.
In my experience, gpt4all worked the easiest out-of-the-box for Mosaic models, but some of the recent updates to the other platforms like oobabooga and koboldcpp have proven to be effective running those as well.
GL, HF, and happy devving!