Changed title because no need for youtube clickbait here
Community to discuss about LLaMA, the large language model created by Meta AI.
This is intended to be a replacement for r/LocalLLaMA on Reddit.
Changed title because no need for youtube clickbait here
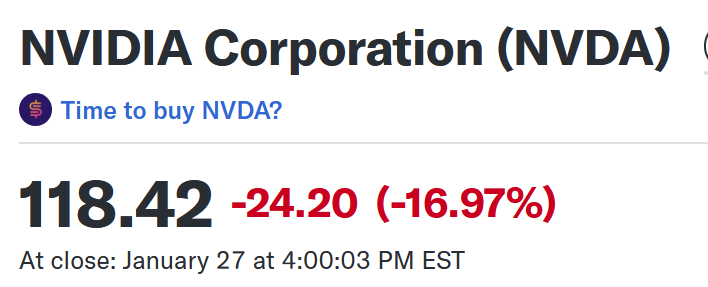
I don't believe so, or at least, them all getting smaller and/or more intelligent isn't the point, it's how they did it
https://stratechery.com/2025/deepseek-faq/