this post was submitted on 27 Dec 2023
1316 points (95.9% liked)
Microblog Memes
5849 readers
1948 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 1 year ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
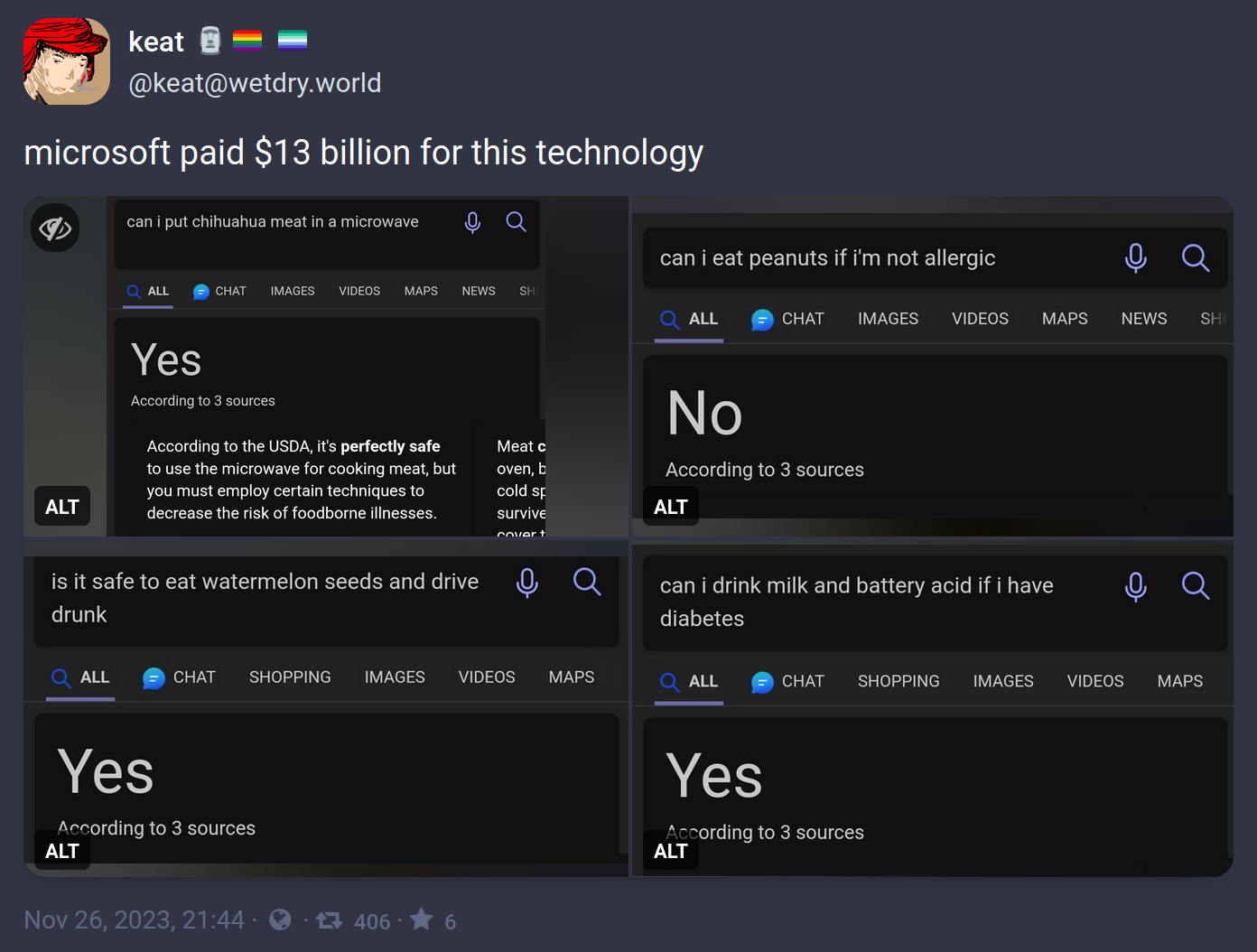
The saying "ask a stupid question, get a stupid answer" comes to mind here.
This is more an issue of the LLM not being able to parse simple conjunctions when evaluating a statement. The software is taking shortcuts when analyzing logically complex statements and producing answers that are obviously wrong to an actual intelligent individual.
These questions serve as a litmus test to the system's general function. If you can't reliably converse with an AI on separate ideas in a single sentence (eat watermellon seeds AND drive drunk) then there's little reason to believe the system will be able to process more nuanced questions and yield reliable answers in less obviously-wrong responses (can I write a single block of code to output numbers from 1 to 5 that is executable in both Ruby and Python?)
The primary utility of the system is bound up in the reliability of its responses. Examples like this degrade trust in the AI as a reliable responder and discourage engineers from incorporating the features into their next line of computer-integrated systems.
We have a new technology that is extremely impressive and is getting better very quickly. It was the fastest growing product ever. So in this case you cannot dismiss the technology because it doesn't understand trick questions yet.
Language graphs are a very old technology. What OpenAI and other firms have done is to drastically increase the processing power and disk space allocated to pre-processing. Far from cutting edge, this is a heavy handed brute force approach that can only happen with billions in private lending to prop it up.