Hi r/Piracy We're excited to announce the launch of our new torrent site, designed with the following goals in mind: Key Features:
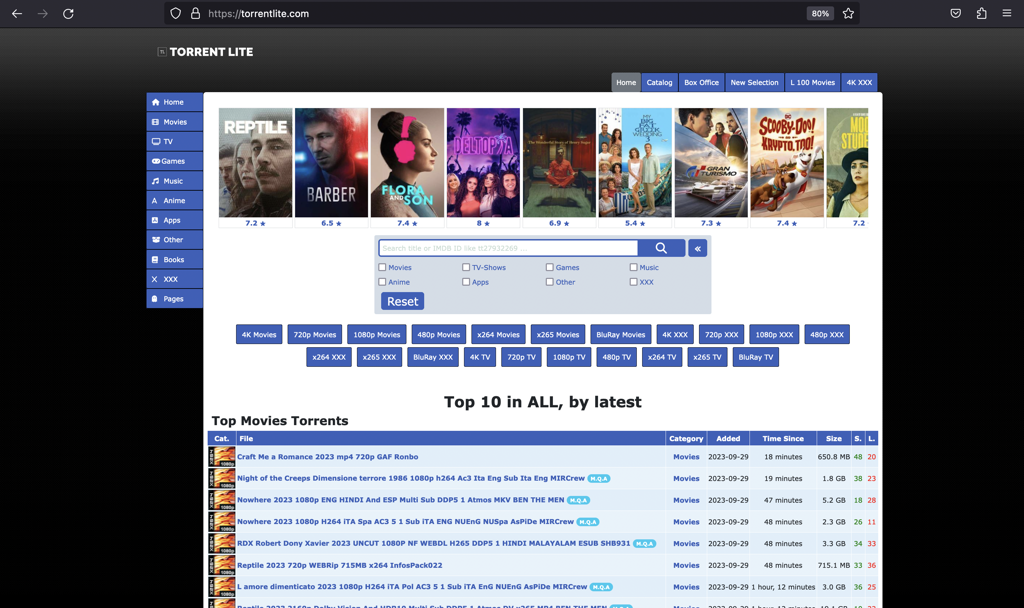
- Clean and user-friendly interface.
- Multiple quality options for each title, accessible via the 'Multiple Quality Available (M.Q.A)' button.
- High-quality torrents sourced from both public and private trackers.
- Hover-over thumbnails for quick previews.
- Search by IMDb ID for easy movie lookup.
- Fast loading times, with pages loading in under 2 seconds.
- Strict content curation, with uploads only by trusted uploaders.
- Access to upcoming movies.
- A comprehensive catalog.
- IMDb summaries for better movie insights.
Front Features We're Working On:
- Dedicated 4K movies section.
- Expanding our library with torrents from more trusted private trackers. We'd greatly appreciate your involvement and feedback. Here's how you can contribute:
- Share your feature suggestions.
- Report any bugs you encounter on the site.
- Join our Lemmy community.
- Become part of our subreddit community.
- You could suggest design changes. Thank you for your support, and we look forward to making our torrent site even better with your input!" Lemmy: https://lemmy.dbzer0.com/c/torrentlite Reddit: https://www.reddit.com/r/TorrentLite/ Website: https://TorrentLite.org/ Mirror: https://TorrentLite.com/ Note: This project is force fork of TRB, but will not have any ties with it soon.
Oh, what I was offering was that I can write the file to do this myself, and then I can submit the PR on github for y’all so it gets done sooner :) I think I’ll be able to figure most of it out with a web inspector but can I PM you or someone else if I have any questions?
Edit: Like, do you know if there’s an API that can respond to requests with JSON or XML? I can make it work with CSS selectors and HTML, but that might make things a lot less efficient on your end. The automation would basically request whole web pages to parse for things like download links. Would still use the RSS feed for new releases, but searching would cause a bigger load if it uses that method.
thanks a lot, css selector are and currently okay, but the way we designed TRB site was anyone can easily get json which can be used to create a page like: example: https://therarbg.com/?format=json correspond to https://therarbg.com/ https://therarbg.com/get-posts/category:Movies:time:10D:format:json/ correspond to https://therarbg.com/get-posts/category:Movies:time:10D/ https://therarbg.com/post-detail/65c2e1/moon-rainbow-lunnaya-raduga-1983-soviet-union-sci-fi/?format=json correspond to https://therarbg.com/post-detail/65c2e1/moon-rainbow-lunnaya-raduga-1983-soviet-union-sci-fi/ so each page work either using ?format=json or adding :format=json as current is fork so same thing works here too.
by any chance you are ilike2burnthing on github ?
Thanks, this is perfect! If I can do it with JSON from the get go I might as well, it won’t be any extra work, they have super clear docs. I’m not, I’m norahqueen on github. :) I can start testing this tonight and tomorrow (AEDT +11).
plese check he have created and subbmitted https://github.com/Jackett/Jackett/issues/14685 so that its not rework.