source
A Beginners Guide To Cron Jobs - OSTechNix
Cron is one of the most useful utility that you can find in any Linux and Unix-like operating system. Cron is used to schedule commands at a specific time. These scheduled commands or tasks are known as "Cron Jobs". Cron is generally used for running scheduled backups, monitoring disk space, deleting files (for example log files) periodically which are no longer required, running system maintenance tasks and a lot more. In this Cron jobs tutorial, we will see the basic usage of Cron Jobs in Linux with examples.
1. The Beginners Guide To Cron Jobs
The typical format of a cron job is:
Minute(0-59) Hour(0-24) Day_of_month(1-31) Month(1-12) Day_of_week(0-6) Command_to_execute
Just memorize the cron job format or print the following illustration and keep it in your desk.
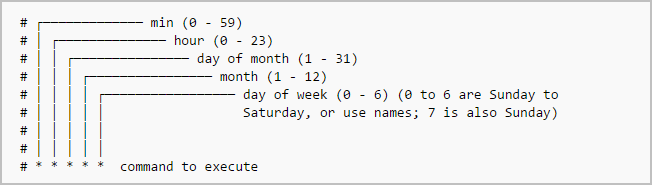
~ ~ ~ ~ Cron job format~ ~ ~ ~
In the above picture, the asterisks refers the specific blocks of time.
To display the contents of the crontab file of the currently logged in user:
$ crontab -l
To edit the current user's cron jobs, do:
$ crontab -e
If it is the first time, you will be asked to choose an editor to edit the cron jobs.
no crontab for sk - using an empty one
Select an editor. To change later, run 'select-editor'.
1. /bin/nano <---- easiest
2. /usr/bin/vim.basic
3. /usr/bin/vim.tiny
4. /bin/ed
Choose 1-4 [1]:
Choose any one that suits you. Here it is how a sample crontab file looks like.
~ ~ ~ ~ crontab file~ ~ ~ ~
In this file, you need to add your cron jobs one by one.
By default, cron jobs run under the user account that created them. However, you can specify a different user by editing the crontab for that user. To edit the crontab of a different user, for example ostechnix, do:
$ sudo crontab -u ostechnix -e
1.1. Cron Jobs tutorial
Here is the list of most commonly used cron job commands with examples. I have also included the detailed explanation for each cron job expression.
1. To run a cron job at every minute, the format should be like below.
* * * * *
This cron job is scheduled to run every minute, every hour, every day, every month, and every day of the week. For example if the time now is 10:00, the next job will run at 10:01, 10:02, 10:03 and so on.
Explanation:
Here is the breakdown of the above cron expression.
The asterisks (*) in each field represent a wildcard, meaning "any value". So, in this case:
- The first asterisk (*) represents any minute (0-59).
- The second asterisk (*) represents any hour (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed every minute.
Please note that running a command every minute can have resource implications and should be used with caution. It's important to ensure that the command you specify is appropriate for frequent execution and does not overload your system.
2. To run cron job at every 5th minute, add the following in your crontab file.
*/5 * * * *
This cron job is scheduled to run every 5 minutes. For example if the time is 10:00, the next job will run at 10:05, 10:10, 10:15 and so on.
Explanation:
Here's how to interpret the cron expression:
- The
*/5 in the first field represents a step value, indicating that the cron job will run every 5 minutes. It matches all values that are divisible evenly by 5 (e.g., 0, 5, 10, 15, 20, etc.).
- The second asterisk (*) represents any hour of the day (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed every 5 minutes.
So, this cron job will run the specified `` every 5 minutes, continuously throughout the day and month, regardless of the specific date or time.
Please keep in mind that running a command at such frequent intervals can generate a high volume of executions. Ensure that the command is suitable for such frequent execution and that it won't overload your system or cause unintended side effects.
3. To run a cron job at every quarter hour (i.e every 15th minute), add this:
*/15 * * * *
For example if the time is 10:00, the next job will run at 10:15, 10:30, 10:45 and so on.
Explanation:
The cron job */15 * * * * is scheduled to run every 15 minutes.
Let's break down the cron expression:
- The
*/15 in the first field represents a step value, indicating that the cron job will run every 15 minutes. It matches all values that are divisible evenly by 15 (e.g., 0, 15, 30, 45, etc.).
- The second asterisk (*) represents any hour of the day (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed every 15 minutes.
Therefore, this cron job will run the specified command every 15 minutes, throughout the day and month, regardless of the specific date or time.
4. To run a cron job every hour at minute 30:
30 * * * *
For example if the time is 10:00, the next job will run at 10:30, 11:30, 12:30 and so on.
Explanation:
The cron job 30 * * * * is scheduled to run at 30 minutes past every hour.
Let's break down the cron expression:
- The
30 in the first field represents the specific minute when the cron job will run. In this case, it's set to 30, so the cron job will execute at 30 minutes past the hour.
- The second asterisk (*) represents any hour of the day (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed at 30 minutes past every hour.
Therefore, this cron job will run the specified command once an hour, specifically at the 30-minute mark. It will execute at 30 minutes past every hour throughout the day and month, regardless of the specific date or day of the week.
Please note that the cron job will not run continuously every minute. Instead, it will run once per hour, always at 30 minutes past the hour.
5. You can also define multiple time intervals separated by commas. For example, the following cron job will run three times every hour, at minute 0, 5 and 10:
0,5,10 * * * *
Explanation:
The cron job 0,5,10 * * * * is scheduled to run at the 0th, 5th, and 10th minute of every hour.
Let's break down the cron expression:
- The
0,5,10 in the first field represents the specific minutes when the cron job will run. In this case, it's set to 0, 5, and 10. The cron job will execute at the 0th, 5th, and 10th minute of every hour.
- The second asterisk (*) represents any hour of the day (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed at the specified minutes.
Therefore, this cron job will run the specified command multiple times within each hour. It will execute at the 0th, 5th, and 10th minute of every hour throughout the day and month, regardless of the specific date or day of the week.
Please note that the cron job will execute only at the specified minutes and not continuously throughout the hour.
6. Run a cron job every half hour i.e at every 30th minute:
*/30 * * * *
For example if the time is now 10:00, the next job will run at 10:30, 11:00, 11:30 and so on.
Explanation:
The cron job */30 * * * * is scheduled to run every 30 minutes.
Here's how to interpret the cron expression:
- The
*/30 in the first field represents a step value, indicating that the cron job will run every 30 minutes. It matches all values that are divisible evenly by 30 (e.g., 0, 30).
- The second asterisk (*) represents any hour of the day (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed every 30 minutes.
Therefore, this cron job will run the specified command every 30 minutes, throughout the day and month, regardless of the specific date or time.
7. Run a job every hour (at minute 0):
0 * * * *
For example if the time is now 10:00, the next job will run at 11:00, 12:00, 13:00 and so on.
Explanation:
The cron job 0 * * * * is scheduled to run at the 0th minute of every hour.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of every hour.
- The second asterisk (*) represents any hour of the day (0-23).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed at the 0th minute of every hour.
Therefore, this cron job will run the specified command once per hour, specifically at the start of each hour. It will execute at the 0th minute of every hour throughout the day and month, regardless of the specific date or day of the week.
Please note that the cron job will not run continuously every minute. Instead, it will run once per hour, precisely at the 0th minute.
8. Run a job every 2 hours:
0 */2 * * *
For example if the time is now 10:00, the next job will run at 12:00.
Explanation:
The cron job 0 */2 * * * is scheduled to run at the 0th minute of every other hour.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of every hour.
- The
*/2 in the second field represents a step value, indicating that the cron job will run every 2 hours. It matches all values that are divisible evenly by 2 (e.g., 0, 2, 4, 6, etc.).
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
The `` represents the actual command that will be executed at the 0th minute of every other hour.
Therefore, this cron job will run the specified command once every 2 hours. It will execute at the 0th minute of every other hour throughout the day and month, regardless of the specific date or day of the week.
Please note that the cron job will not run continuously every minute or every hour. Instead, it will run once every 2 hours, precisely at the 0th minute of those hours.
9. Run a job every day (It will run at 00:00):
0 0 * * *
Explanation:
The cron job 0 0 * * * is scheduled to run at midnight (00:00) every day.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed at midnight (00:00) every day.
Therefore, this cron job will run the specified command once per day, precisely at midnight. It will execute at 00:00 hours every day, regardless of the specific date or day of the week.
Please note that the cron job will run once per day, specifically at midnight, to perform the task defined by the command.
10. Run a job every day at 3am:
0 3 * * *
Explanation:
The cron job 0 3 * * * is scheduled to run at 3:00 AM every day.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
3 in the second field represents the specific hour when the cron job will run. In this case, it's set to 3, which corresponds to 3:00 AM.
- The third asterisk (*) represents any day of the month (1-31).
- The fourth asterisk (*) represents any month (1-12).
- The fifth asterisk (*) represents any day of the week (0-7).
- The `` represents the actual command that will be executed at 3:00 AM every day.
Therefore, this cron job will run the specified command once per day, specifically at 3:00 AM. It will execute at 3:00 AM every day, regardless of the specific date or day of the week.
11. Run a job every Sunday:
0 0 * * SUN
Or,
0 0 * * 0
It will run at exactly at 00:00 on Sunday.
The cron job will run once per week, specifically at midnight on Sundays, to perform the task defined by the command.
Explanation:
The cron job 0 0 * * SUN is scheduled to run at midnight (00:00) on Sundays.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The asterisks (*) in the third and fourth fields represent any day of the month (1-31) and any month (1-12), respectively.
- The
SUN in the fifth field represents the specific day of the week when the cron job will run. In this case, it's set to SUN, indicating Sundays.
- The `` represents the actual command that will be executed at midnight on Sundays.
Therefore, this cron job will run the specified command once per week, specifically at midnight on Sundays. It will execute at 00:00 hours every Sunday, regardless of the specific date or month.
12. Run a job on every day-of-week from Monday through Friday i.e every weekday:
0 0 * * 1-5
The job will start at 00:00.
The cron job will run once per day, specifically at midnight, from Monday to Friday, to perform the task defined by the command.
Explanation:
The cron job 0 0 * * 1-5 is scheduled to run at midnight (00:00) from Monday to Friday.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The asterisks (*) in the third and fourth fields represent any day of the month (1-31) and any month (1-12), respectively.
- The
1-5 in the fifth field represents the range of days of the week when the cron job will run. In this case, it's set to 1-5, indicating Monday to Friday.
- The `` represents the actual command that will be executed at midnight from Monday to Friday.
Therefore, this cron job will run the specified command once per day, specifically at midnight, from Monday to Friday. It will execute at 00:00 hours on weekdays, regardless of the specific date or month.
13. Run a job every month (i.e at 00:00 on day-of-month 1):
0 0 1 * *
The cron job will run once per month, specifically at midnight on the 1st day of the month, to perform the task defined by the command.
Explanation:
The cron job 0 0 1 * * is scheduled to run at midnight (00:00) on the 1st day of every month.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The
1 in the third field represents the specific day of the month when the cron job will run. In this case, it's set to 1, indicating the 1st day of the month.
- The asterisks (*) in the fourth and fifth fields represent any month (1-12) and any day of the week (0-7), respectively.
- The `` represents the actual command that will be executed at midnight on the 1st day of every month.
Therefore, this cron job will run the specified command once per month, specifically at midnight on the 1st day of each month. It will execute at 00:00 hours on the 1st day of the month, regardless of the specific month or day of the week.
14. Run a job at 16:15 on day-of-month 1:
15 16 1 * *
The cron job will run once per month, specifically at 4:15 PM (16:15) on the 1st day of the month, to perform the task defined by the command.
Explanation:
The cron job 15 16 1 * * is scheduled to run at 4:15 PM (16:15) on the 1st day of every month.
Here's how to interpret the cron expression:
- The
15 in the first field represents the specific minute when the cron job will run. In this case, it's set to 15, so the cron job will execute at 15 minutes past the hour.
- The
16 in the second field represents the specific hour when the cron job will run. In this case, it's set to 16, which corresponds to 4:00 PM.
- The
1 in the third field represents the specific day of the month when the cron job will run. In this case, it's set to 1, indicating the 1st day of the month.
- The asterisks (*) in the fourth and fifth fields represent any month (1-12) and any day of the week (0-7), respectively.
- The `` represents the actual command that will be executed at 4:15 PM on the 1st day of every month.
Therefore, this cron job will run the specified command once per month, specifically at 4:15 PM on the 1st day of each month. It will execute at 16:15 hours on the 1st day of the month, regardless of the specific month or day of the week.
15. Run a job at every quarter i.e on day-of-month 1 in every 3rd month:
0 0 1 */3 *
The cron job will run once every three months, specifically at midnight on the 1st day of the applicable month, to perform the task defined by the command.
Explanation:
The cron job 0 0 1 */3 * is scheduled to run at midnight (00:00) on the 1st day of every third month.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The
1 in the third field represents the specific day of the month when the cron job will run. In this case, it's set to 1, indicating the 1st day of the month.
- The
*/3 in the fourth field represents a step value, indicating that the cron job will run every 3rd month. It matches all values that are divisible evenly by 3 (e.g., 1, 4, 7, 10).
- The asterisks (*) in the fifth field represent any day of the week (0-7).
- The `` represents the actual command that will be executed at midnight on the 1st day of every third month.
Therefore, this cron job will run the specified command once every three months, specifically at midnight on the 1st day of each applicable month. It will execute at 00:00 hours on the 1st day of every third month, regardless of the specific day of the week.
16. Run a job on a specific month at a specific time:
5 0 * 4 *
The job will start at 00:05 in April. The cron job will run once per day, specifically at 12:05 AM, during the month of April, to perform the task defined by the command.
Explanation:
The cron job 5 0 * 4 * is scheduled to run at 12:05 AM (00:05) every day during the month of April.
Here's how to interpret the cron expression:
- The
5 in the first field represents the specific minute when the cron job will run. In this case, it's set to 5, so the cron job will execute at 5 minutes past the hour.
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The asterisk (*) in the third field represents any day of the month (1-31).
- The
4 in the fourth field represents the specific month when the cron job will run. In this case, it's set to 4, indicating April.
- The asterisk (*) in the fifth field represents any day of the week (0-7).
- The `` represents the actual command that will be executed at 12:05 AM every day in April.
Therefore, this cron job will run the specified command once per day, specifically at 12:05 AM, during the month of April. It will execute at 00:05 hours on each day of April, regardless of the specific day of the week.
17. Run a job every 6 months:
0 0 1 */6 *
This cron job will start at 00:00 on day-of-month 1 in every 6th month. The cron job will run once every six months, specifically at midnight on the 1st day of the applicable month, to perform the task defined by the command.
Explanation:
The cron job 0 0 1 */6 * is scheduled to run at midnight (00:00) on the 1st day of every 6th month.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The
1 in the third field represents the specific day of the month when the cron job will run. In this case, it's set to 1, indicating the 1st day of the month.
- The
*/6 in the fourth field represents a step value, indicating that the cron job will run every 6th month. It matches all values that are divisible evenly by 6 (e.g., 1, 7, 13).
- The asterisks (*) in the fifth field represent any day of the week (0-7).
- The `` represents the actual command that will be executed at midnight on the 1st day of every 6th month.
Therefore, this cron job will run the specified command once every six months, specifically at midnight on the 1st day of each applicable month. It will execute at 00:00 hours on the 1st day of every 6th month, regardless of the specific day of the week.
18. Run a job on the 1st and 15th of every month:
0 0 1,15 * *
This cron job is scheduled to run on the 1st and 15th of every month at midnight (00:00). The cron job will run twice per month, specifically at midnight on the 1st and 15th days, to perform the task defined by the command.
Explanation:
The cron job 0 0 1,15 * * is scheduled to run at midnight (00:00) on the 1st and 15th day of every month.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The
1,15 in the third field represents the specific days of the month when the cron job will run. In this case, it's set to 1 and 15, indicating the 1st and 15th day of the month.
- The asterisks (*) in the fourth and fifth fields represent any month (1-12) and any day of the week (0-7), respectively.
- The `` represents the actual command that will be executed at midnight on the 1st and 15th day of every month.
Therefore, this cron job will run the specified command twice per month, specifically at midnight on the 1st and 15th day of each month. It will execute at 00:00 hours on the 1st and 15th days, regardless of the specific month or day of the week.
19. Run a job every year:
0 0 1 1 *
This cron job will start at 00:00 on day-of-month 1 in January. The cron job will run once per year, specifically at midnight on January 1st, to perform the task defined by the command.
Explanation:
The cron job 0 0 1 1 * is scheduled to run at midnight (00:00) on the 1st day of January.
Here's how to interpret the cron expression:
- The
0 in the first field represents the specific minute when the cron job will run. In this case, it's set to 0, so the cron job will execute at the start of the hour (00 minutes).
- The
0 in the second field represents the specific hour when the cron job will run. In this case, it's set to 0, which corresponds to midnight.
- The
1 in the third field represents the specific day of the month when the cron job will run. In this case, it's set to 1, indicating the 1st day of the month.
- The
1 in the fourth field represents the specific month when the cron job will run. In this case, it's set to 1, indicating January.
- The asterisk (*) in the fifth field represents any day of the week (0-7).
- The `` represents the actual command that will be executed at midnight on the 1st day of January.
Therefore, this cron job will run the specified command once per year, specifically at midnight on the 1st day of January. It will execute at 00:00 hours on January 1st, regardless of the specific day of the week.
Using Cron Job Strings:
We can also use the following strings to define a cron job.
| Cron job strings |
Action |
| @reboot |
Run once, at startup. |
| @yearly |
Run once a year. |
| @annually |
(same as @yearly). |
| @monthly |
Run once a month. |
| @weekly |
Run once a week. |
| @daily |
Run once a day. |
| @midnight |
(same as @daily). |
| @hourly |
Run once an hour. |
Supported Cron strings
20. To run a job every time the server is rebooted, add this line in your crontab file.
@reboot
Explanation:
The code @reboot is not a cron job syntax. Instead, it is a special directive that can be used in the cron configuration file.
When the @reboot directive is used in the cron configuration file, it indicates that the specified `` should be run once when the system reboots or starts up.
Here's how it works:
- When the system boots up or restarts, the cron daemon reads the cron configuration file.
- If a cron job has the
@reboot directive followed by a ``, the specified command is executed at that time.
- The command can be any valid command or script that you want to run when the system starts up.
Therefore, using @reboot in the cron configuration file allows you to schedule a command or script to run automatically once when the system boots up.
Please note that the availability and usage of the @reboot directive may vary depending on the specific cron implementation and system configuration.
21. To remove all cron jobs for the current user:
$ crontab -r
The command crontab -r is used to remove or delete the current user's crontab (cron table) entries.
When you execute crontab -r, it removes all the scheduled cron jobs associated with your user account. This action is irreversible, and the cron jobs will no longer be executed as per their previously scheduled times.
It's important to exercise caution when using this command because it permanently deletes all the cron jobs for your user account, including any recurring tasks or scheduled commands.
Before running crontab -r, ensure that you have a backup or make sure you no longer need the existing cron jobs. If you accidentally delete your crontab, it may not be recoverable unless you have a backup.
To confirm the removal of your crontab, the command usually displays a message such as "crontab: no crontab for ," indicating that the cron table has been successfully removed.
If you wish to edit your crontab in the future, you will need to create new cron entries using crontab -e or restore from a backup if available.
22. For cron job detailed usage, check man pages.
$ man crontab
At this stage, you might have a basic understanding of what is Crontab and how to create, run and manage cron jobs in Linux and Unix-like systems.
Now we will learn about some graphical tools which helps us to make the cron job management a lot easier.
2. Crontab syntax generators
As you can see, scheduling cron jobs is much easier. Also there are a few web-based crontab syntax generators available to make this job even easier. You don't need to memorize and/or learn crontab syntax.
The following two websites helps you to easily generate a crontab expression based on your inputs. Once you generated the line as per your requirement, just copy/paste it in your crontab file.
2.1. Crontab.guru
Crontab.guru is dedicated website for learning cron jobs examples. Just enter your inputs in the site and it will instantly create a crontab syntax in minutes.
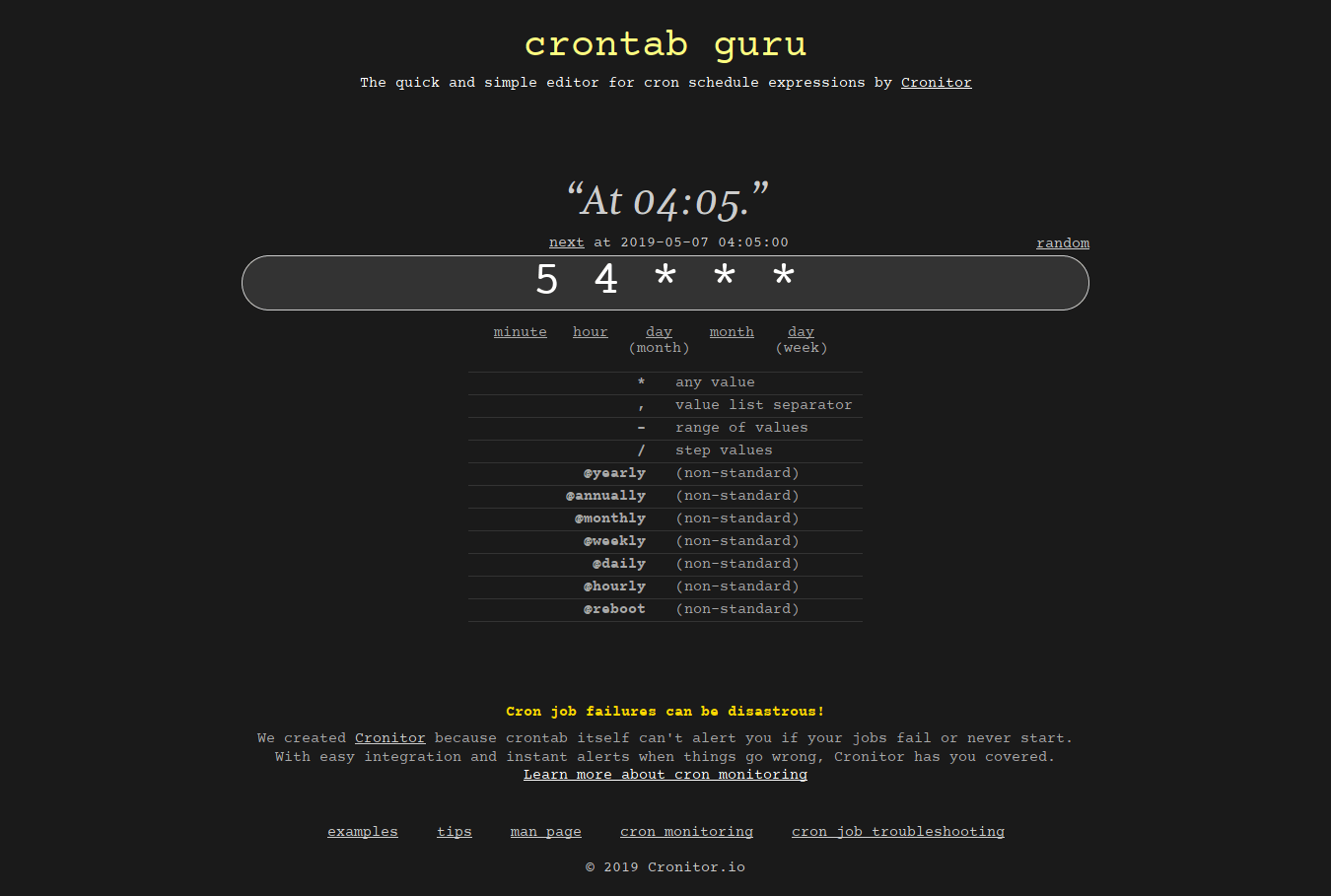
Crontab guru - A quick and simple editor for cron schedule expressions
This site also provides a lot of cron job examples and tips. Do check them and learn how to schedule a cronjob.
2.2. Crontab Generator
This has been pointed out by one of our reader Mr.Horton in the comment section below.
Crontab Generator is yet another website that helps us to quickly and easily generate crontab expressions. A form that has multiple entries is given in this site. The user must choose all required fields in the form.
Finally, hit the "Generate Crontab Line" button at the bottom.
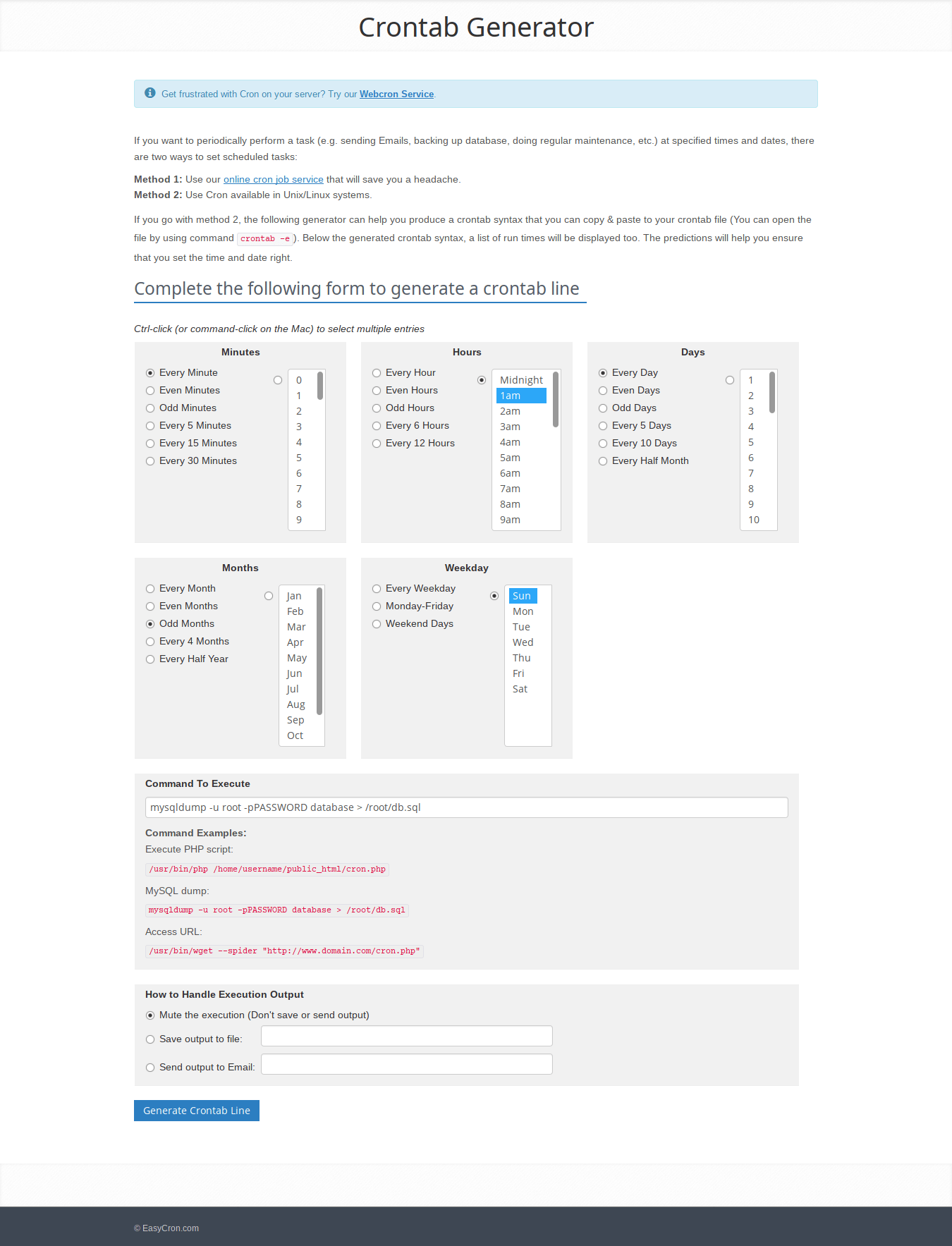
Crontab Generator - Easily generate crontab expressions
In the next screen, the user will see his/her crontab expression. Just copy/paste it to the crontab file. It is that simple.
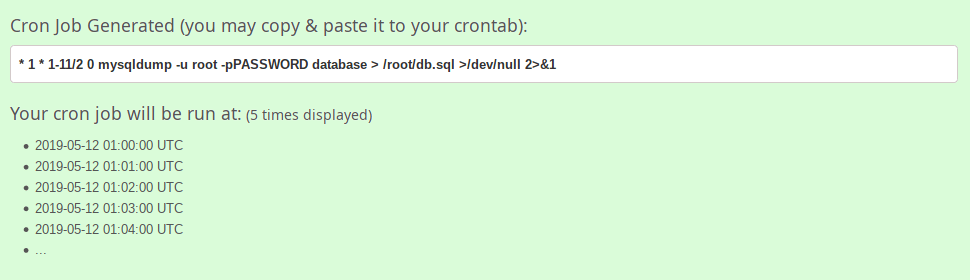
Generate crontab entries using Crontab Generator
Easy, isn't? Both of these websites will definitely help the newbies who don't have much experience in creating cron jobs.
Remember to review and verify the generated cron syntax from these tools before using it in your cron configuration to ensure it aligns with your requirements and environment.
3. Crontab graphical front-ends
There are a few Crontab front-end tools available to easily create cron jobs via a graphical interface. No need to edit the Crontab file from command line to add or manage cron jobs! These tools will make cron job management much easier!
3.1. Crontab UI
Crontab UI is a web-based tool to easily and safely manage cron jobs in Linux. You don't need to manually edit the crontab file to create, delete and manage cron jobs. Everything can be done via a web browser with a couple mouse clicks.
Crontab UI allows you to easily create, edit, pause, delete, backup cron jobs and also import, export and deploy jobs on other machines without much hassle.
Have a look at the following link if you're interested to read more about it.
3.2. Zeit
Zeit is a Qt front-end to crontab and at command. Using Zeit, we can add, edit and delete cron jobs via simple graphical interface. For more details, refer the following link:
4. Frequently Asked Questions
Here's an FAQ (Frequently Asked Questions) for Cron jobs.
Q: What is a Cron job?
A: A Cron job is a time-based task scheduler in Linux and Unix-like operating systems. It allows you to schedule and automate the execution of commands or scripts at specified intervals, such as minutes, hours, days, or months.
Q: How do I create a Cron job?
A: To create a Cron job, you can use the crontab command to edit your user-specific cron table. Run crontab -e to open the table in a text editor and add your desired cron job entry using the specified cron syntax.
Q: What is the cron syntax?
A: The cron syntax consists of five fields: minute, hour, day of month, month, and day of week. Each field allows you to specify the desired time or condition for the job to run. For example, 0 12 * * * represents a cron job scheduled to run at 12:00 PM every day.
Q: How do I specify multiple values in a field?
A: You can use commas (,) to specify multiple values within a field. For example, 1,15 * * * * means the job will run at the 1st and 15th minute of every hour.
Q: Can I use step values in the cron syntax?
A: Yes, you can use step values. For example, */15 * * * * means the job will run every 15 minutes. It matches all values divisible evenly by 15.
Q: How can I specify the user for a cron job?
A: By default, cron jobs run under the user account that created them. However, you can specify a different user by using sudo crontab -u username -e to edit the crontab for that particular user.
Q: How do I view existing cron jobs?
A: To view the existing cron jobs for your user, run crontab -l. This command lists the contents of your current crontab.
Q: How do I remove a cron job?
A: To remove a cron job, run crontab -e to edit your crontab and delete the corresponding entry. Alternatively, you can use crontab -r to remove all cron jobs for your user.
Q: Are there any web-based tools available to help generate cron job syntax?
A: Yes, there are web-based crontab syntax generators that can assist you in creating cron job schedules without needing to memorize the syntax. Some notable examples include Crontab.guru and Crontab Generator. These tools allow you to interactively select the desired schedule using user-friendly interfaces and generate the corresponding cron job syntax for you.
These web-based tools can be helpful, especially for those who are new to cron jobs or need a quick way to generate complex schedules. However, it's still important to understand the basics of cron syntax to effectively use and troubleshoot cron jobs in various environments.
Q: Are there any graphical interfaces or front-end tools available for managing cron jobs?
A: Yes, there are Crontab front-end tools that provide graphical interfaces to easily create and manage cron jobs without needing to edit the Crontab file manually from the command line.
Notable examples of such tools include Crontab UI and Zeit. These tools typically offer user-friendly interfaces where you can define cron job schedules, specify the commands or scripts to run, set environment variables, and manage multiple cron jobs in a visual manner.
5. Conclusion
In this Cron tab tutorial, we discussed what is a cron job, and the basic usage of cron jobs in Linux with example commands.
We also discussed a few web-based crontab syntax generators and crontab graphical front-ends which are used to easily create and manage cron jobs in Linux. Finally, we have listed some most commonly asked questions and answers (FAQ) for Cron Jobs.
Resources: