crossposted from https://wandering.shop/@meredithw/113983437672884349
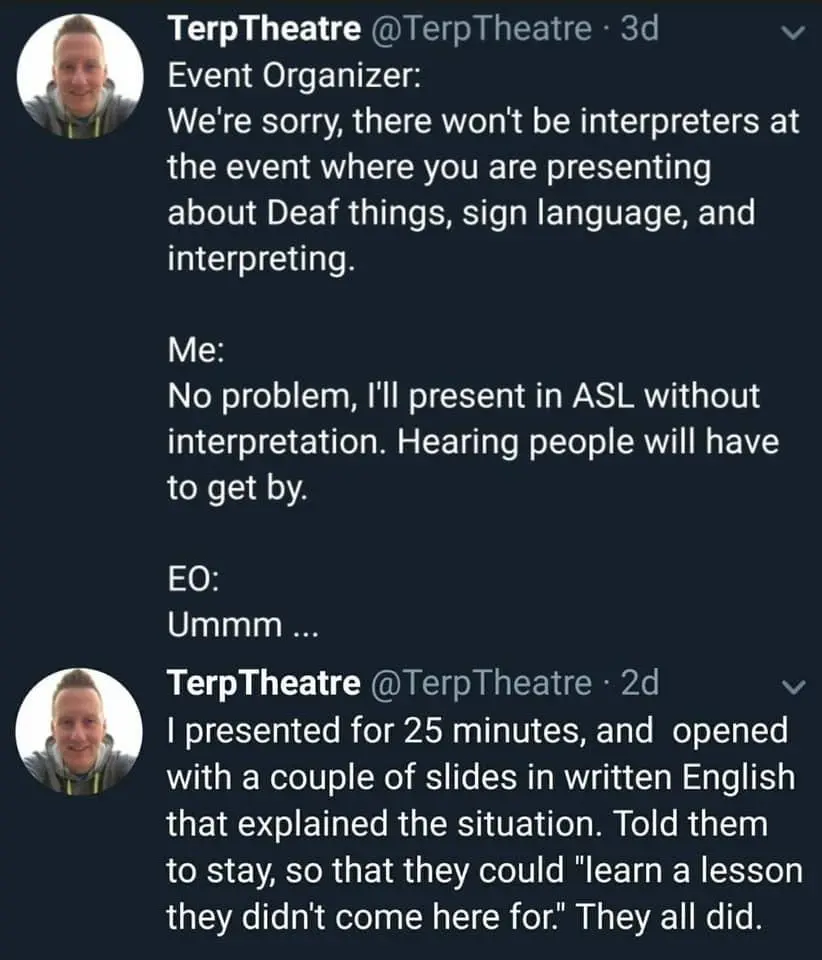
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
Related communities:
crossposted from https://wandering.shop/@meredithw/113983437672884349
Honestly I think that sort of training is largely already over. The datasets already exist (have for over a decade now), and are largely self-training at this point. Any training on new images is going to be done by looking at captions under news images, or through crawling videos with voiceovers. I don't think this is a going concern anymore.
And, incidentally, that kind of dataset just isn't very valuable to AI companies. Most of the use they're going to get is in being able to create accessible image descriptions for visually-disabled people anyway; they don't really have a lot more value for generative diffusion models beyond the image itself, since the aforementioned image description models are so good.
In short, I really strongly believe that this isn't a reason to not alt-text your images.
Maybe the AI can alt text it for us.
It sort of can. Firefox is using a small language model to do just that, in one of the more useful accessibility implementations of machine learning. But it's never going to be capable of the context that human alt text, from the uploader, can give.